
BERTの学習で用いるoptimizerでbiasやlayer normalizationのパラメータだけがweight decayの対象外となっていることについて疑問は持ったことはあるでしょうか。たとえばhuggingfaceのtransformersのissueでもそのような質問がありますが、「Googleの公開しているBERTがそうしているから再現性のために合わせた」と回答されています。ではなぜGoogleのBERT実装はそのような設定にしたのでしょうか。これらのOSSを利用されている方にも天下り的に設定している方もいらっしゃると思います。本記事ではBERTなどの学習で用いられるoptimizerのweight decayで、biasやlayer normalizationのパラメータが対象外となっている理由について解説します。

本記事ではWNGT 2020のefficiencyシェアドタスクに提出されたEfficient and High-Quality Neural Machine Translation with OpenNMTを紹介します。 このタスクでは精度だけではなく、省メモリ、高速であることに焦点を当てています。 自然言語処理タスクの多くはニューラルネットワークに基づく巨大なモデルによって最高精度が塗り替えられていますが、実用上は精度以外にもメモリや速度の観点を検討しなければならない場面が多く、現実に即したタスクとなっています。 紹介する論文では機械翻訳で実験を行っていますが、その他のタスクに対しても適用できそうなテクニックが多く、勉強になりそうだったので紹介することにしました。 このタスクに参加した他のシステムも精度や速度などの指標においてパレート曲線状にあり、それぞれのシステムが重きをおいた指標が異なっています。 本記事で紹介する論文は速度、省メモリに焦点を当てています。

本記事ではOn the Stability of Fine-tuning BERT: Misconceptions, Explanations, and Strong Baselinesという論文を紹介します。 この論文ではBERTのfine-tuningが安定しにくいという問題に対して、単純で良い結果が得られる方法を提案しています。 またBERTのfine-tuningが安定しにくいという問題を細かく分析しており、参考になったのでそのあたりについてもまとめます。 本記事を読むことでBERTを自分の問題でfine-tuningするときの施策を立てやすくなるかと思います。
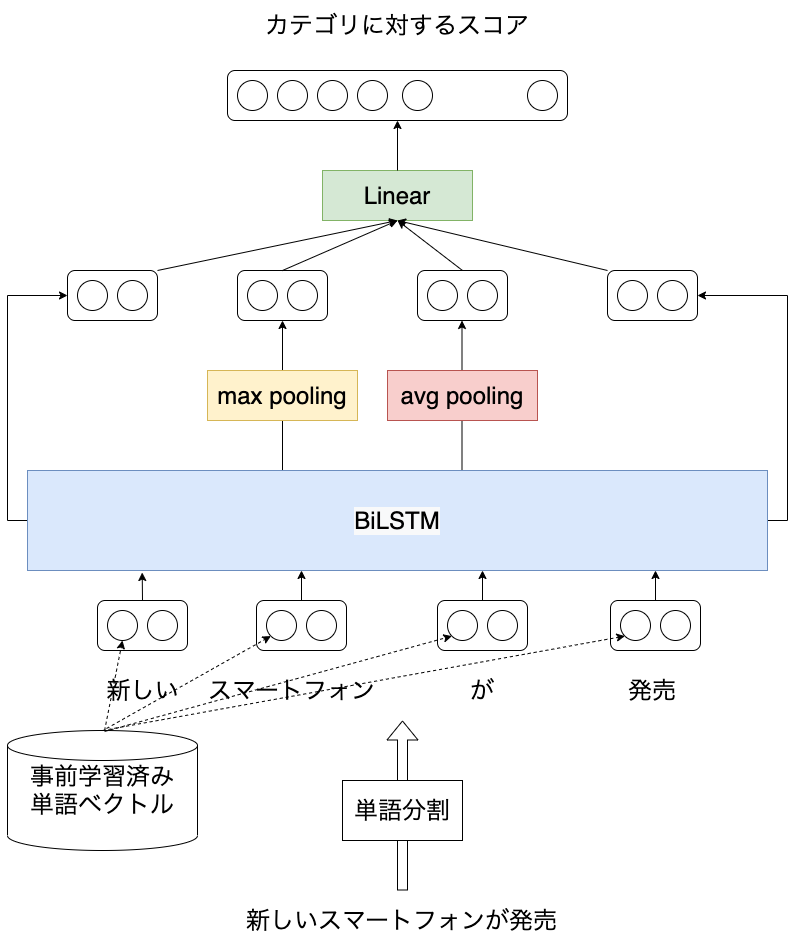
本記事では日本語を対象としたLSTMに基づく文書分類モデルをPyTorchコード付きで紹介します。 以前、LSTMを用いた言語モデルについて紹介しました ( [自然言語処理] LSTMに基づく言語モデルの学習 (PyTorchコード付き) ) が、ニューラルネットワークを用いた自然言語処理の応用例として文書分類のほうがイメージしやすそうなので、こちらについても紹介したいと思います。 実験にはライブドアコーパスから作成した、記事の見出しに対して9つのカテゴリのうち、どれか1つが付与されたデータを使います。 本記事を読むことで日本語を対象に、ニューラルネットワークを活用した自然言語処理の概要を知ることができます。 また、PyTorchで事前学習済みの単語分散表現を扱う方法も紹介しています。
本記事では画像認識系の国際会議 ECCV2020のチュートリアルでNVIDIAが発表した資料 PYTORCH PERFORMANCE TUNING GUIDE の内容をまとめるとともに、理解の助けになるような関連情報を参照します。 PyTorchは簡単にニューラルネットワークの実装のを容易さだけでなく、処理速度にも注意を払って開発が進められています。 プログラムにほんの少し修正を加えるだけで高速化できる可能性があります。 本記事を読み、実践することで、手元のPyTorchプログラム (特にGPUを使った学習処理) を高速化できる可能性があります。

ニューラル言語モデルはこれまでのn-gram言語モデルと比較して流暢なテキストを生成することができます。 ニューラル言語モデルの学習にはTeacher-forcingという方法がよく用いられます。 この手法はニューラル言語モデルの学習がしやすい一方で、テキスト生成時の挙動と乖離があります。 本記事では、Teacher-forcingを説明するとともに、この手法の課題を改善するための手法であるScheduled samplingを紹介します。
Kaggleの文書分類タスクにおける参加者のtipsがText Classification: All Tips and Tricks from 5 Kaggle Competitionsにまとまっていました。英語が前提になっているものの、参考になったので目を通し、概要をまとめました。 また日本語を対象とした場合に参考になりそうな記事も挙げておきます。
