【自然言語処理】 あなたのBERTに対するfine-tuningはなぜ失敗するのか 【論文紹介】
本記事ではOn the Stability of Fine-tuning BERT: Misconceptions, Explanations, and Strong Baselinesという論文を紹介します。 この論文ではBERTのfine-tuningが安定しにくいという問題に対して、単純で良い結果が得られる方法を提案しています。 またBERTのfine-tuningが安定しにくいという問題を細かく分析しており、参考になったのでそのあたりについてもまとめます。 本記事を読むことでBERTを自分の問題でfine-tuningするときの施策を立てやすくなるかと思います。
目次
本記事で掲載する図や表は紹介する論文から引用しています。
紹介する論文で提案する方法でBERTをfine-tuningすることで、Figure 1のように学習が安定し、かつ平均的にも高い評価尺度が得られるようになります。
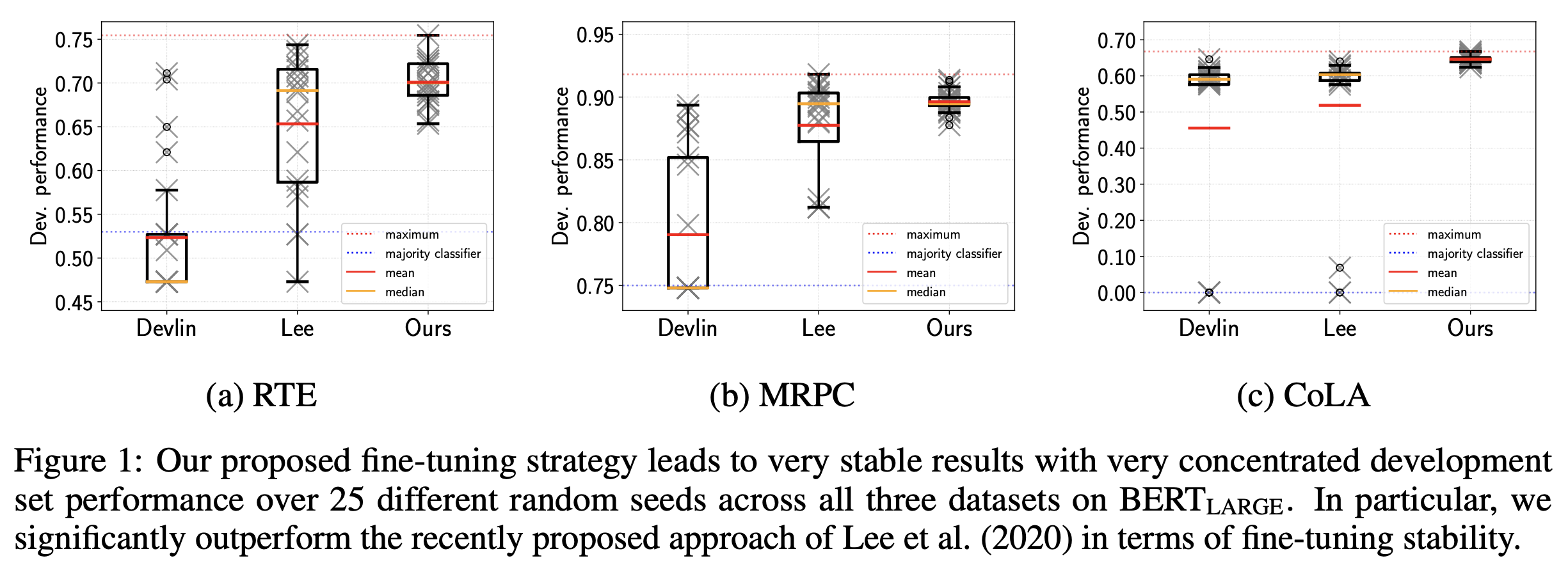 Fiure 1。既存fine-tuningの比較結果
Fiure 1。既存fine-tuningの比較結果
fine-tuningが失敗する原因とされていること
従来fine-tuningが失敗する原因とされていること:
- 破滅的忘却
- 学習データ量が少ないこと
破滅的忘却は、「ここではfine-tuningによってpre-trainingで学習したパラメータから大きく変わってしまい、pre-trainingによってできるようになっていたことができなくなってしまうような現象」です。
一方で、紹介する論文が主張する、fine-tuning失敗する原因はoptimizationにおける勾配消失にあるとしています。 この仮設を検証するために、BERT, RoBERTa, ALBERTといったBERT系の手法をGLUEに含まれるベンチマークデータで実証しています。
従来のfine-tuning失敗の原因に関する調査
まずfine-tuningが失敗する原因としてよく言及される破滅的忘却と、学習データの量が少ないことに着目し、検証実験をおこないます。
検証に利用するデータ
- CoLA: 与えられた文が文法的かそうでないかを予測するタスク
- MPRC: 2つの文が与えられたとき、片方がもう片方の文の言い換えであるかそうでないかを予測するタスク
- RTE: 2つの文の含意関係を認識するタスク
fine-tuning失敗の基準
本記事で紹介する論文では、「fine-tuningを終えたBERTの評価データにおける評価尺度が、そのタスクのベースラインのそれよりも低い」場合、fine-tuningに失敗したBERTとしています。
破滅的忘却がfine-tuningの失敗を引き起こすのか?
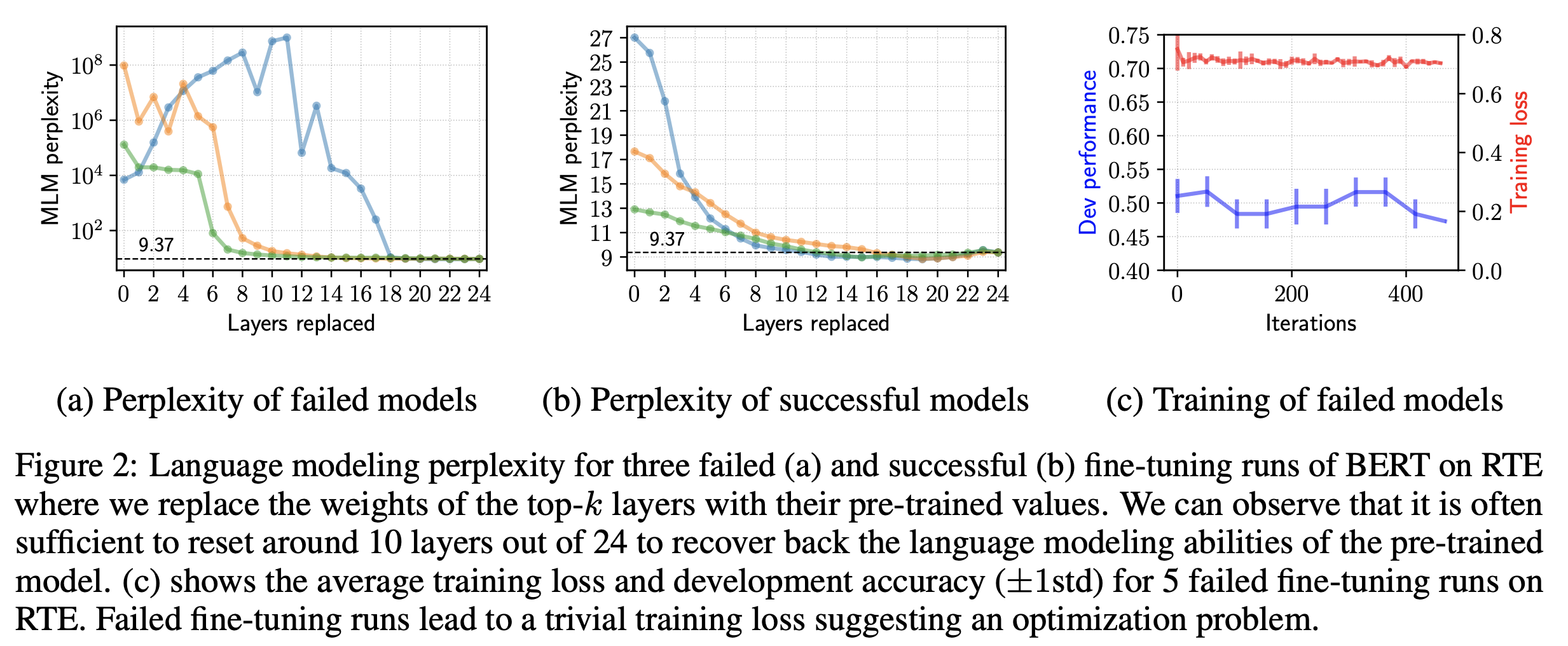 破滅的忘却がfine-tuningの失敗に及ぼす影響の検証実験。
破滅的忘却がfine-tuningの失敗に及ぼす影響の検証実験。
破滅的忘却は、一般的に言うと、2つの異なるタスクに対して、逐次的にニューラルネットワークを学習するとき、2つ目のタスクを学習すると、1つ目のタスクに対してうまく予測ができなくなったしまうような現象です。
本記事で紹介する論文では、pre-trainingをしてからfine-tuningするという2つのタスクを逐次的に処理する流れになります。 そのため、破滅的忘却が起きているのならば 「fine-tuning後、pre-trainingのタスク、つまり単語の穴埋めをするような問題がうまく解けなくなっている」 ことになります。
破滅的忘却が起きているかどうかを計測するために、BERTの上位層を事前学習時の学習結果に変えて、pre-trainingのタスクがうまく解けているかを評価します。 評価尺度にはpre-trainingデータに対するパープレキシティ (ここでは穴埋めされた箇所に対して、正解の単語の生成確率をうまく予測できているかどうかを表すような指標)を用います。
実験ではfine-tuningが成功したBERTと、fine-tuningが失敗したBERTのパープレキシティを比較します。 結果を見ると、上位のTransformer層 (10層目まで) をpre-training時の学習結果にすると、破滅的忘却 (パープレキシティが高い) が起きているようです (fine-tuning後の上位の層の学習結果はpre-trainingのそれと大きく変わっているということです)。 ただし、 破滅的忘却はfine-tuningの成否にかかわらず起きています。
また、破滅的忘却は通常、少なくとも後段のタスク、つまりfine-tuningが成功していることが前提になりますが、fine-tuningが失敗したBERTは、そうではありません。 Figure 2(c)を見ると、含意関係認識タスクのfine-tuningが失敗したBERTは、学習時の損失が小さくなっているのにも関わらず、開発データにおけるaccuracyがベースラインと同程度となっており、学習はできているものの、よく汎化できていないことが示唆されます。
これらのことから、 fine-tuningの失敗の原因はoptimizationにあって、それがBERTの上位層における破滅的忘却を引き起こしているのではないかと推測されます。
学習データが少ないことがfine-tuningの失敗を引き起こすのか?
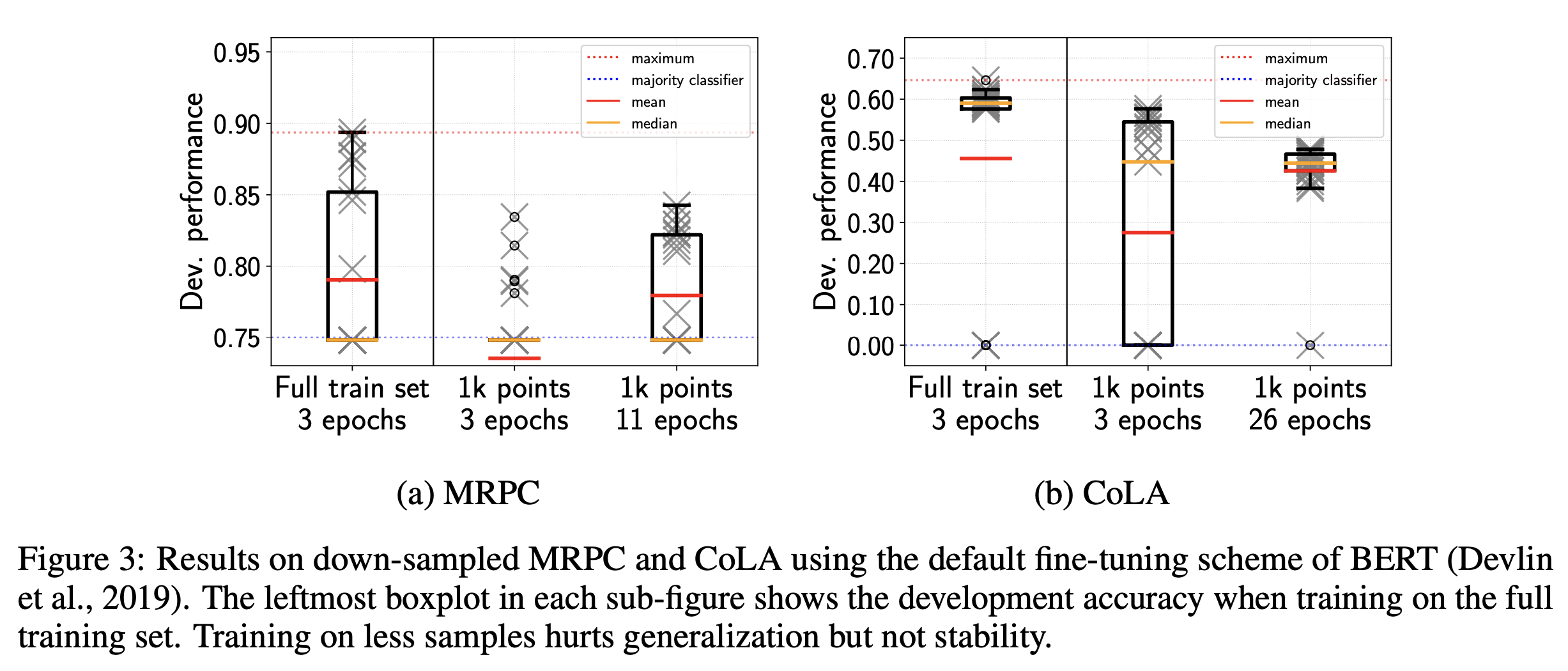 Fiure 3
Fiure 3
次に学習データの量が少ないことがfine-tuningの失敗の原因となるかを実験に基づいて検証します。 実験では学習データを少量にサンプリングし、次の2つの設定を比較します。
- 少量にサンプリングした学習データでfine-tuning
- 少量にサンプリングした学習データでfine-tuning。ただし、学習データをすべて使った場合と同じ数のiterationだけパラメータを更新する。
学習データの量が少ないことが問題であるならば、1と2で同等の結果となることが期待されます。
しかしながら、実験結果 (Figure 3) から観測できることは以下のとおりです。
- 学習データの量を減らすとfine-tuningの失敗に影響する
- 学習データの量を減らすと汎化性能が低下する
- 学習データの量を減らしても減らさない場合と同じだけのiteration回数だけパラメータを更新すると、学習が安定しやすくなる
これらのことから、 学習データの量が少ないことは、学習の安定性とは関係がないこと、学習の安定に影響するのはiteration回数であることを示唆しています。
fine-tuning失敗の理由はoptimizationにある
破滅的忘却と学習データの量が少ないことはfine-tuningの失敗と相関があるものの、それらが原因とは言えないことを見てきました。
optimizationに関する調査
fine-tuningを失敗したBERTは勾配消失が起きている
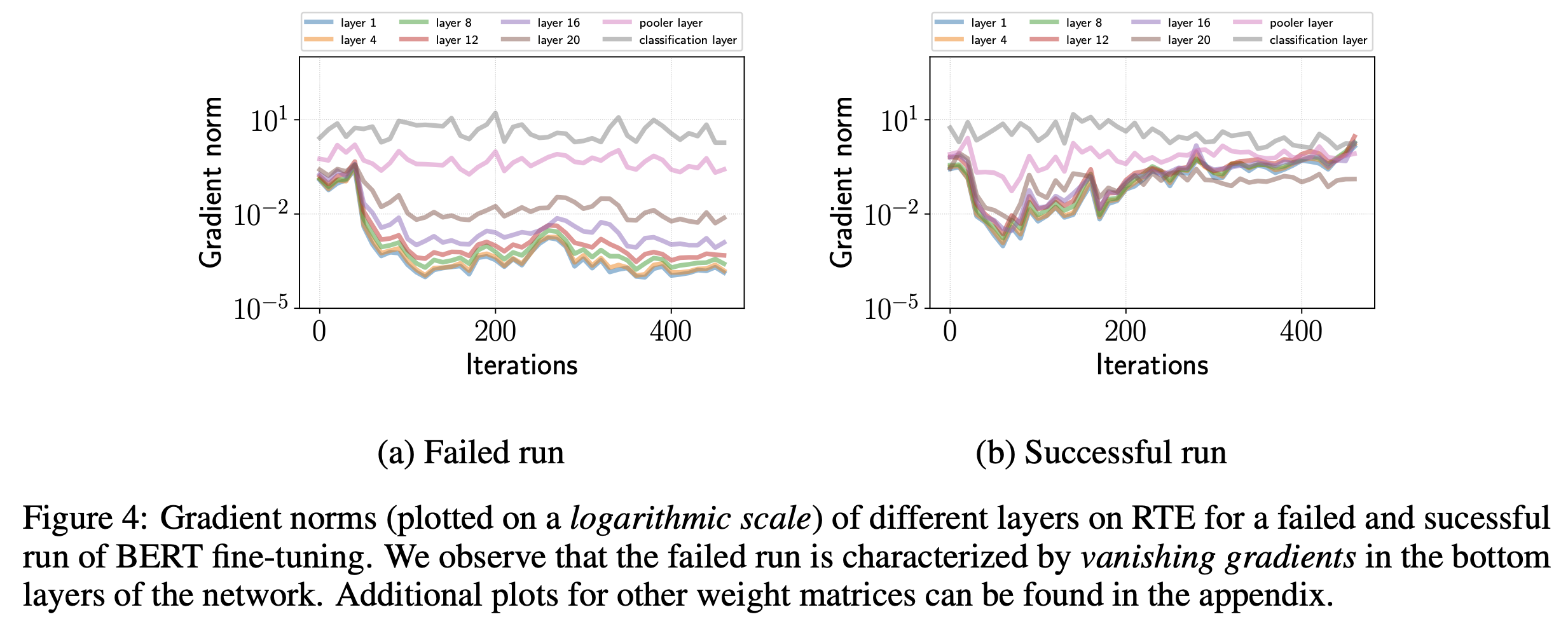 Transformer層の勾配の大きさ
Transformer層の勾配の大きさ
Figure 2(c) では学習時の損失がほとんど変化していませんでした。 この現象を調査するために、fine-tuningが成功したBERTと、失敗したBERTの各層における勾配の大きさ (L2ノルム) を計測しています (Figure 4)。 Figure 4から、fine-tuningが失敗したBERTは、学習が進むと入力に近い層で勾配の大きさが小さくなっていることが確認できます。 このことから、fine-tuningが失敗したBERTは、勾配消失が起きており、パラメータがほとんど更新されず、学習の損失が変わらなかったと推測できます。
またfine-tuningにおける勾配消失は、通常の勾配消失よりも解決が難しいことを言及しています。 なぜなら、パラメータの初期化方法は、学習が安定して進むような研究が進められていますが、pre-trainingしたモデルのパラメータを修正してしまうと、pre-trainingで学習した結果を変えてしまうことになるので、単純な方法ではパラメータの修正ができないためです。
オリジナルのBERTのfine-tuneにおけるoptimizationはバイアス補正を利用していない
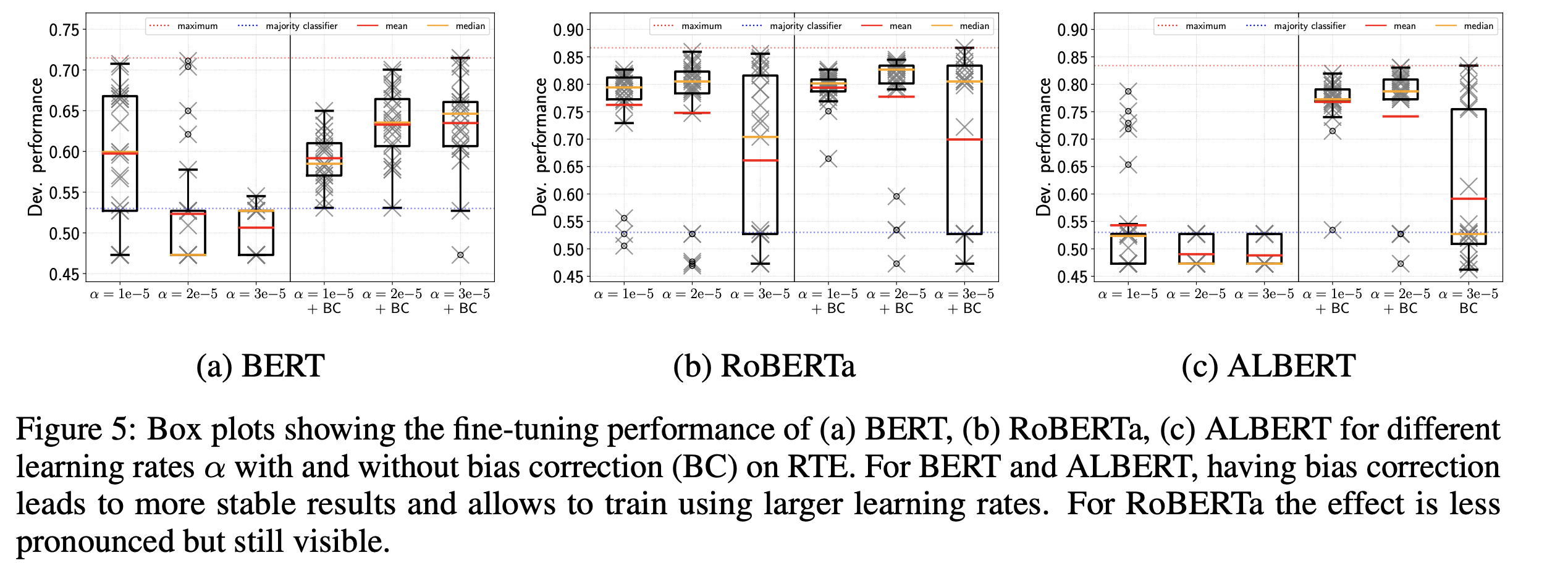 学習率・バイアス補正の影響
学習率・バイアス補正の影響
Adamのバイアス補正は、BERTの学習でよく用いられるwarm up trainingと同様の効果を持つことを言及しています。 Figure 5はバイアス補正あり・なしのAdamでfine-tuningを実施したモデルの比較結果を表しています。 BERTの元論文ではバイアス補正なしのAdamを用いています1が、Figure 5から、バイアス補正ありのAdamを用いることが安定的な学習につながることを示しています。
fine-tuningに失敗したBERTは局所解に陥っている
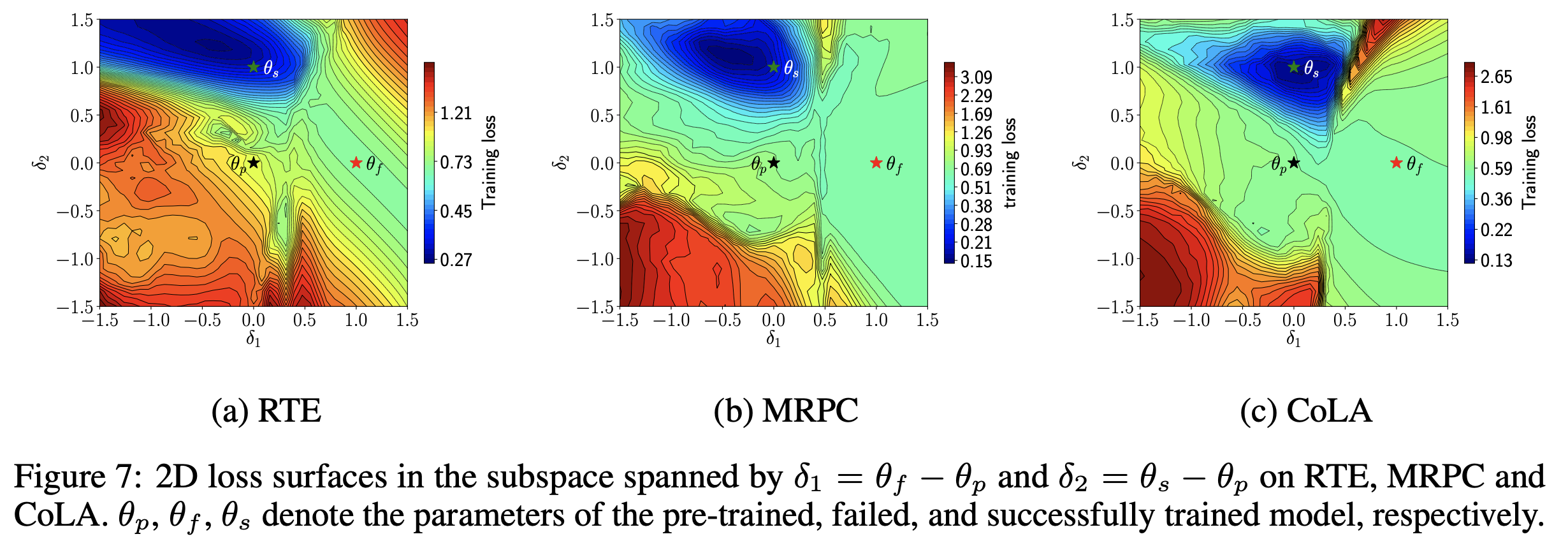 損失の形状。青色ほど損失の値が低い。
損失の形状。青色ほど損失の値が低い。
fine-tuningの失敗を直感的に理解するために、fine-tuningに成功したBERTと失敗したBERTの損失の形状を可視化しています (Figure 7)。 fine-tuningに失敗したBERT ($\theta_f$) は局所解に陥っていること、成功したBERT ($\theta_s$) はより損失が小さな解が求められていることがわかります。 fine-tuningに失敗したBERTは局所解に陥ったあたりで勾配消失が起き、パラメータが更新されないため、そこから抜け出せなくなっているというのが視覚的にわかります。
generalizationに関する調査
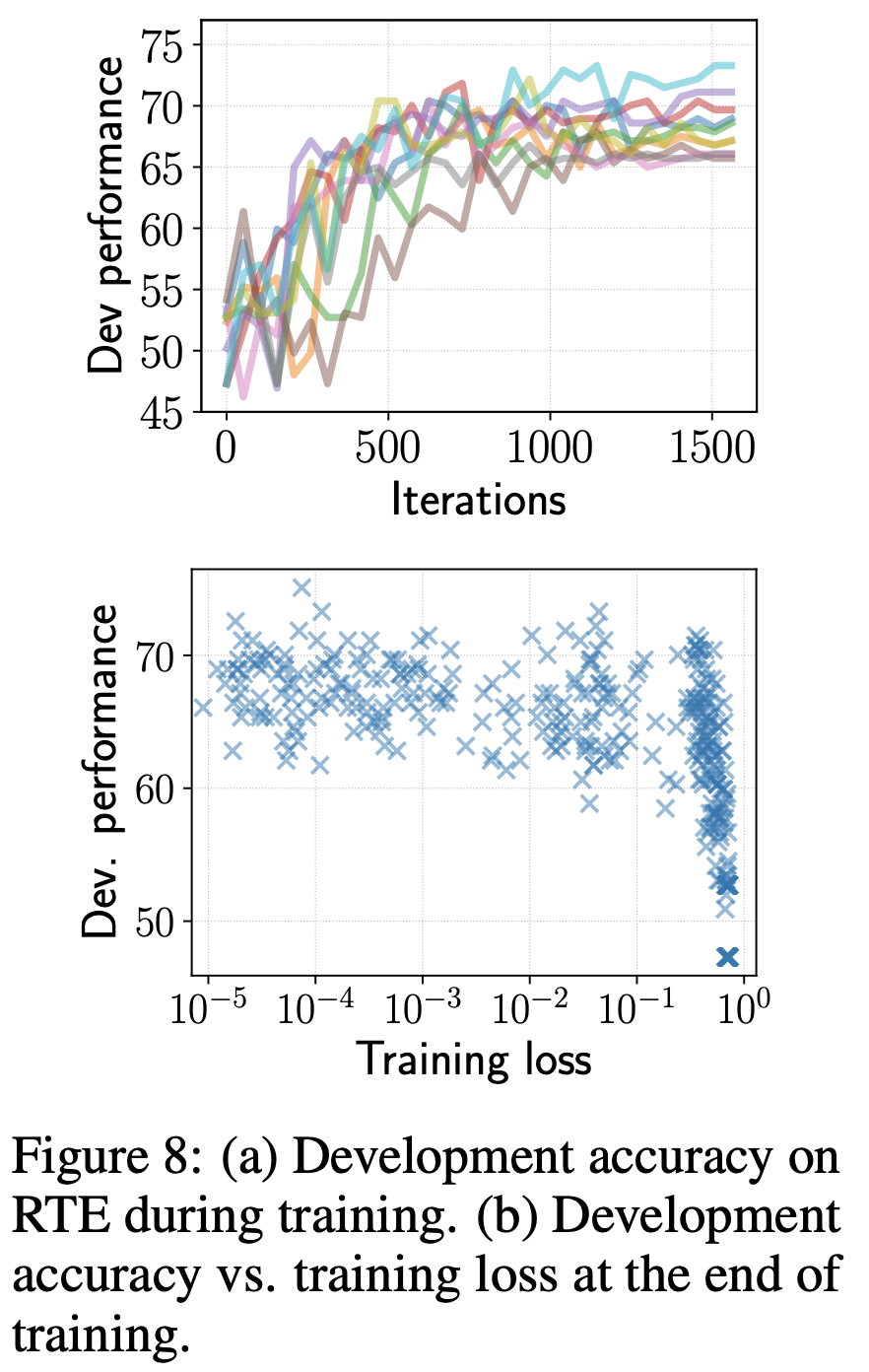 iteration回数と汎化性能の関係・学習データにおける損失と汎化性能の関係
iteration回数と汎化性能の関係・学習データにおける損失と汎化性能の関係
これまでにoptimizationが学習の安定に与える影響を見てきました。 次は汎化性能と学習の安定について調査します。
Figure 8はBERTのデフォルトの設定でのfine-tuneを10回実施して得られた結果です。 Figure 8(a)はfine-tuningに成功したBERTの開発データにおけるaccuracyです。 Figure 8(b)はfine-tuningの成否にかかわらず、すべてのBERTの実験における学習時の損失と開発データにおけるaccuracyです。
Figure 8(a)から iterationを増やすと開発データにおけるaccuracyが改善されている ことがわかります。 また、Figure 8(b)から fine-tuningの成否にかかわらず、学習時の損失が小さい方が開発データにおけるaccuracyが高い ことがわかります。
これらのことから、 過学習はfine-tuningにおいては問題ではない ことがいえます。また、 学習のiterationを増やすことで、汎化性能が改善されている ことがいえます。
BERTをfine-tuningするときに検討したいこと
ではどうすれば安定的にBERTのfine-tuningを成功されられるのでしょうか。 本記事で紹介している論文では以下を提案し、実験によって有効性を評価しています。
単純だけど強力なfine-tuningのコツ
- 学習時初期における勾配消失をさけるために、バイアス補正つきのoptimizationと、小さな学習率を使う
- 学習のiteration回数を増やし、early stoppingを使いつつも学習時の損失を小さくする
| BERTのfine-tuningの設定 | 紹介論文のfine-tuningの設定 | |
|---|---|---|
| optimizer | バイアス補正のないAdamW | AdamW |
| エポック数 | 3 | 20 |
| 学習の終了基準 | なし | 開発データにおけるタスクの評価尺度が改善しなくなったら終了 |
実験結果
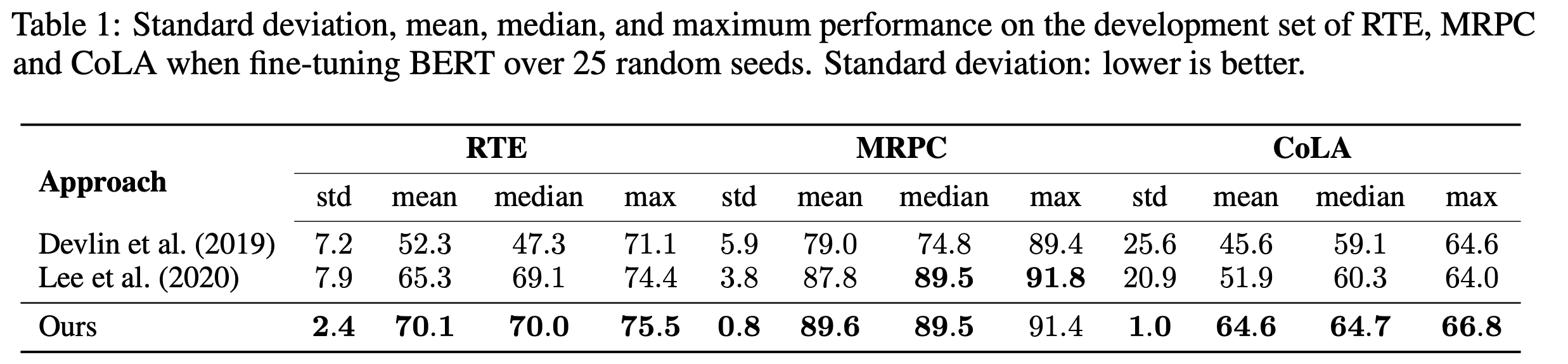 実験結果
実験結果
Table 1に実験結果が示されています。 実験結果から、上記の設定を利用することで、毎回乱数を変えて実験しても評価尺度が安定するだけではなく、平均的に見てもBERTのデフォルトの設定よりも良い結果が得られています。
提案手法は学習のエポック数が増えるため、計算コストが増えるという懸念事項もあります。 一方で、提案手法は学習が安定しやすいため、何度も実験を繰り返さなくてもよい結果が得られます。
おわり
本記事ではOn the Stability of Fine-tuning BERT: Misconceptions, Explanations, and Strong Baselinesという論文を紹介しました。 紹介した論文ではBERTのfine-tuningが安定しにくいという問題に対して、単純で良い結果が得られる方法を提案しました。