[自然言語処理] LSTMに基づく言語モデルの学習 (PyTorchコード付き)
単語の系列 (たとえば文や文書) に対して確率を割り当てるようなモデルは言語モデルと呼ばれています。 古くはN-gram言語モデルが用いられました。 最近ではより広い文脈を考慮したり、単語スパースネスの問題に対処できるニューラルネットワークに基づく言語モデル (ニューラル言語モデル) が良く用いられます。 ニューラル言語モデルは文書分類、情報抽出、機械翻訳などの自然言語処理の様々なタスクで用いられます。 本記事ではコード付きでLSTMに基づく言語モデルおよびその学習方法を説明します。 本記事を読むことで、LSTMに基づく言語モデルの概要、学習の流れを理解できます。
目次
本記事で掲載しているコードは以下のようにライブラリを利用します。
import collections
import math
import os
import random
import shutil
import time
import torch
import torch.nn.functional as F
またPyTorchは1.4.0を利用しています。
語彙
ニューラル言語モデルを実装するにあたり、モデルが扱う単語の集合 (語彙) を扱うクラスを作成します。 このクラスは単語を対応するindexに変換したり、その逆の処理をするために用います。
class Vocabulary:
def __init__(self):
self.index2item = []
self.item2index = {}
def __len__(self):
return len(self.item2index)
def __contains__(self, item):
return item in self.item2index.keys()
def add_item(self, item):
index = len(self.item2index)
self.index2item.append(item)
self.item2index[item] = index
def get_item(self, index):
return self.index2item[index]
def get_index(self, item):
return self.item2index[item]
def save(self, vocab_file):
with open(vocab_file, 'w') as f:
for word in self.item2index:
print(word, file=f)
@classmethod
def load(cls, vocab_file):
vocab = cls()
with open(vocab_file) as f:
for line in f:
word = line.strip()
vocab.item2index[word] = len(vocab.item2index)
vocab.index2item.append(word)
return vocab
LSTMに基づく言語モデル
言語モデルは単語列 $(x_1, x_2, …, x_n)$ に対して生成確率 $p(x_1, x_2, …, x_n)$を割り当てます。 生成確率は以下のように分解することができます。
$$
\begin{eqnarray}
p(x_1,…, x_n) &=& p(x_1|h_1) p(x_2|h_2) p(x_3|h_3) … p(x_n|h_n) \\\
&=& \Pi_{k=1}^{n} p(x_k|h_{k})
\end{eqnarray}
$$
$p(x_k|h_k)$ は隠れ状態 $h_k$ が与えられたときの単語 $x_k$ の生成確率を表すものとします。 また $p(x_k|h_k)$ は以下のように計算します。
$$ p(x_k|h_k) = \frac{\exp(w_{x_k} h_k)}{\sum_{\bar{x}} \exp(w_{\bar{x}} h_k)} $$
$h_t$ はLSTMによって計算された文脈情報のようなもので、直前のLSTMの出力を用いて再帰的に計算します。この式はsoftmax関数と呼ばれています。$w$は学習対象のパラメータです。
$$ h_k, c_k = f(e_{x_{k-1}}, h_{k-1}, c_{k-1}) $$
$f$ はLSTMの隠れ状態を計算する関数とします。 $e_{x_{k-1}}$ は$x_{k-1}$ に対して割り当てる分散表現とします。
LSTMに基づく言語モデルの概要図は以下のようになります。 まず単語を対応する分散表現に変換します (Embedding)。 次に、LSTMへ分散表現と、直前のLSTMの出力を入力し、現在の出力を得ます (LSTM)。 LSTMの出力に基づいて、語彙に登録されている単語数の次元に線形変換します (Linear)。 最後に、正解の単語の負の対数尤度を計算します (CrossEntropy)。
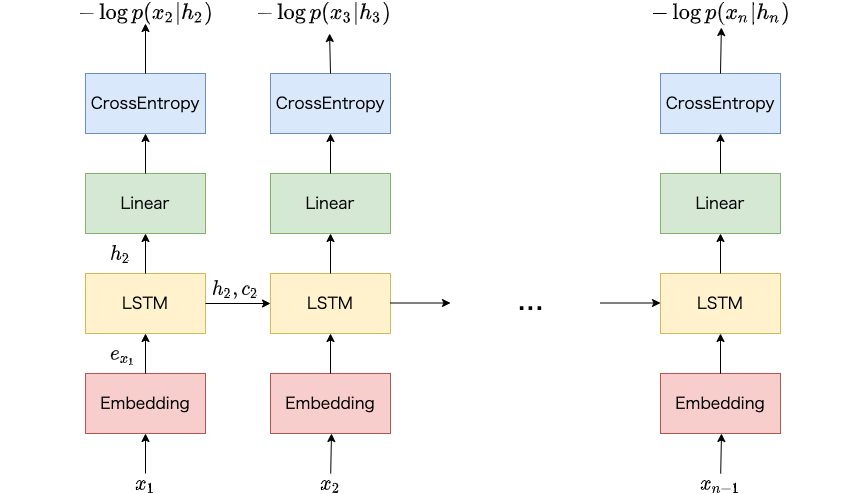 LSTMに基づく言語モデルの概要図
LSTMに基づく言語モデルの概要図
PyTorchで実装するのは非常に簡単で、単語列を与えて、softmax層で確率として正規化する直前の値までを計算するのは3行でかけます。
class LanguageModel(torch.nn.Module):
def __init__(
self,
vocab,
dim_emb=128,
dim_hid=256):
super().__init__()
self.vocab = vocab
self.embed = torch.nn.Embedding(len(vocab), dim_emb)
self.rnn = torch.nn.LSTM(dim_emb, dim_hid, batch_first=True)
self.out = torch.nn.Linear(dim_hid, len(vocab))
def forward(self, x, state=None):
x = self.embed(x)
x, (h, c) = self.rnn(x, state)
x = self.out(x)
return x, (h, c)
def generate(self, start=None, max_len=100):
if start is None:
start = random.choice(self.vocab.index2item)
idx = self.embed.weight.new_full(
(1, 1),
self.vocab.get_index(start),
dtype=torch.long)
decoded = [start]
state = None
unk = self.vocab.get_index('<unk>')
for i in range(max_len):
x, state = self.forward(idx, state)
x[:, :, unk] = -float('inf')
idx = torch.argmax(x, dim=-1)
word = self.vocab.get_item(idx.item())
decoded.append(word)
return ' '.join(decoded)
言語モデルの学習における処理手順
ニューラルネットワークの実装よりも大変なのが実際にデータを読みこんで学習処理を実施する箇所です。
前処理 (語彙の構築と単語をindexへ変換)
前処理では語彙を構築して、単語列をindexの列に変換する処理を実装します。
class Preprocessor:
def __init__(
self,
data_file,
bin_dir='data-bin',
vocab_file = 'vocab',
n_max_word=10000,
num_token_per_file=1000000,
force_preprocess=False):
self.data_file = data_file
self.vocab_file = vocab_file
self.n_max_word = n_max_word
self.num_token_per_file = num_token_per_file
self.bin_dir = bin_dir
self.force_preprocess = force_preprocess
def run(self):
if self.force_preprocess:
vocab = self._build_vocab()
shutil.rmtree(self.bin_dir)
self._binarize_text(vocab)
if not os.path.exists(self.vocab_file):
vocab = self._build_vocab()
else:
vocab = Vocabulary.load('vocab')
if not os.path.exists(self.bin_dir):
self._binarize_text(vocab)
語彙の構築は以下の関数で実装します。 パディング用の特殊単語、語彙に登録されていない単語 (未知語) を表す単語および出現頻度が高い上位の単語集合を語彙とします。
def _build_vocab(self):
counter = collections.Counter()
with open(self.data_file) as f:
for line in f:
words = line.strip().split()
for word in words:
counter[word] += 1
vocab = Vocabulary()
vocab.add_item('<pad>')
vocab.add_item('<unk>')
for word, _ in counter.most_common(self.n_max_word - 2):
vocab.add_item(word)
vocab.save(self.vocab_file)
return vocab
単語列をindexの列に変換する処理は以下の関数で実装します。 ある程度行数が多いデータは、分割して保存するようにします。
def _binarize_text(self, vocab):
data = []
unk = vocab.get_index('<unk>')
if not os.path.exists(self.bin_dir):
os.makedirs(self.bin_dir)
num_file = 0
num_token = 0
with open(self.data_file) as f:
lines = []
for line in f:
lines.append(line)
random.shuffle(lines)
for line in lines:
words = line.strip().split()
indices = [vocab.get_index(word) if word in vocab
else unk for word in words]
data += indices
num_token += len(indices)
if len(data) >= self.num_token_per_file:
data = torch.tensor(data)
torch.save(data, f'{self.bin_dir}/{num_file}.pt')
num_file += 1
batch = []
if not os.path.exists(self.bin_dir):
os.makedirs(self.bin_dir)
data = torch.tensor(data)
torch.save(data, f'{self.bin_dir}/{num_file}.pt')
print(f'Data size: {num_token}')
また保存したデータは以下のように読み込んで使います。 ここでは指定されたindexに対応するファイルのデータを読み込んで返すだけです。
class Dataset(torch.utils.data.Dataset):
def __init__(self, data_dir):
self.filenames = [os.path.join(data_dir, p) for p in os.listdir(data_dir)]
def __len__(self):
return len(self.filenames)
def __getitem__(self, index):
tensor = torch.load(self.filenames[index])
return tensor
学習部分 (Truncated Backpropagation Through Time)
学習時は以下のような負の対数尤度を損失関数 $L$ として得られた勾配に基づいて言語モデルのパラメータ $\theta$ を学習します。 負の対数尤度が小さくなるほど、学習データ中の単語列に対して高い生成確率を割り当てることができます。
$$
\begin{eqnarray}
L(\theta) &=& -\log p(x_1, …, x_n) \\\
&=& - \sum_{k=1}^{n} \log p(x_k|h_{k})
\end{eqnarray}
$$
単語列が長いほど、保持しなければならない勾配の数が大きくなり、消費メモリの増加や計算速度の低下につながります。
実用的には、単語列の先頭から末尾まですべてを一度に処理してパラメータを更新せず、単語列を部分的に処理してパラメータを更新します。
具体的にはTruncated Backpropagation Through Time (TBPTT) という方法でLSTMに基づく言語モデルを学習します。 以下にTBPTTの概要図を示します。
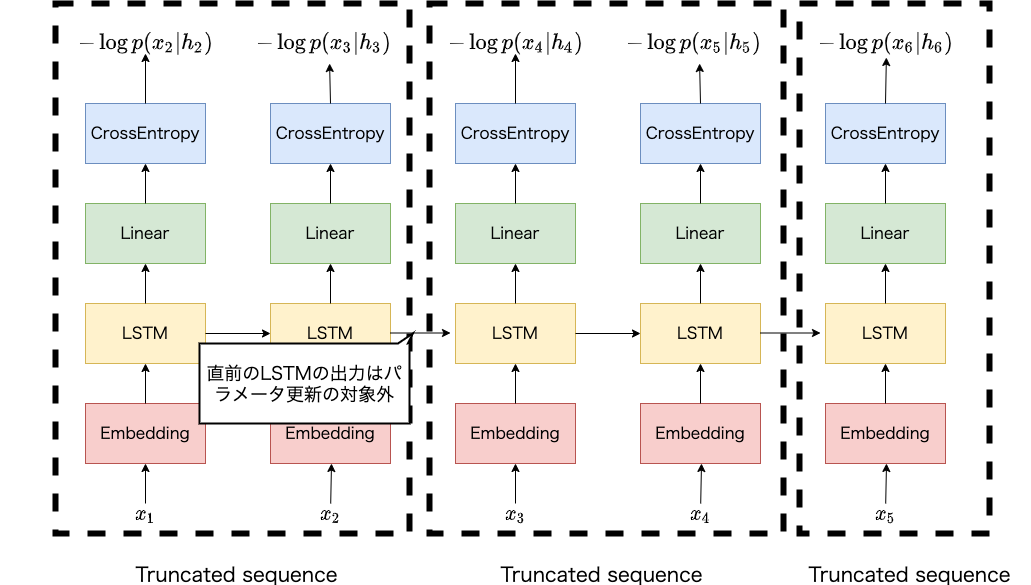 TBPTTの概要図。枠線単位で損失を計算してパラメータを更新する。LSTMの隠れ状態は直前の出力で初期化しますが、その出力はパラメータ更新の対象にはなりません。
TBPTTの概要図。枠線単位で損失を計算してパラメータを更新する。LSTMの隠れ状態は直前の出力で初期化しますが、その出力はパラメータ更新の対象にはなりません。
単語列の長さが5の事例に対して、固定長の長さ2で単語列を分割し、先頭から順に部分列を対象に損失を計算し、得られた勾配に基づいてパラメータを更新します。直前のLSTMの隠れ状態は、直前の部分列のLSTMの出力を用います。この出力は、現在の部分列を用いてパラメータを更新する際の対象とはなりません。このように処理することで、単語列を分割して処理することができるため、消費メモリの増加や計算速度の低下を改善することができます。
def collate_fn(batch):
return batch[0]
class LanguageModelTrainer:
def __init__(
self,
model,
optimizer,
data_dir,
device,
max_epochs=10,
batch_size = 32,
log_interval=200,
sequence_length=250,
clip=0.25):
self.model = model
self.optimizer = optimizer
self.model.to(device)
self.device = device
self.max_epochs = max_epochs
self.batch_size = batch_size
self.log_interval = log_interval
self.clip = clip
self.sequence_length = sequence_length
self.dataset = Dataset(data_dir)
TBPTTを実装しているのは以下の箇所です。
def train(self):
print('Run trainer')
pad = self.model.vocab.get_index('<pad>')
data_loader = torch.utils.data.DataLoader(
self.dataset,
shuffle=True,
collate_fn=collate_fn,
num_workers=2)
start_at = time.time()
for epoch in range(self.max_epochs):
loss_epoch = 0.
num_token = 0
step = 0
for data in data_loader:
# batchfy
num_batch = data.size(0) // self.batch_size
data = data.narrow(0, 0, num_batch * self.batch_size)
batch = data.view(self.batch_size, -1)
state = None
for seen_batch, i in enumerate(range(0, batch.size(1), self.sequence_length), start=1):
e = min(i + self.sequence_length, batch.size(1))
batch_i = batch[:, i: e]
batch_i = batch_i.to(self.device)
step += 1
input_i = batch_i[:, :-1]
target_i = batch_i[:, 1:]
x, (h, c) = self.model(input_i, state)
vocab_size = x.size(2)
num_token_i = (target_i != pad).sum().item()
loss = F.nll_loss(
F.log_softmax(x, dim=-1).contiguous().view(-1, vocab_size),
target_i.contiguous().view(-1),
reduction='sum',
ignore_index=pad)
self.optimizer.zero_grad()
loss.div(num_token_i).backward()
torch.nn.utils.clip_grad_norm_(self.model.parameters(), self.clip)
self.optimizer.step()
num_token += num_token_i
loss_epoch += loss.item()
h = h.clone().detach()
c = c.clone().detach()
state = (h, c)
if step % self.log_interval == 0:
elapsed = time.time() - start_at
print(f'epoch:{epoch} step:{step}'
f' loss:{loss_epoch/num_token:.2f}'
f' elapsed:{elapsed:.2f}')
loss_epoch /= num_token
ppl = math.exp(loss_epoch)
elapsed = time.time() - start_at
print('-' * 50)
print(f'epoch:{epoch} loss:{loss_epoch:.2f}'
f' ppl:{ppl:.2f} elapsed:{elapsed:.2f}')
decoded = self.model.generate()
print(f'Sampled: {decoded}')
print('-' * 50)
以下の関数を実装し、Google Colaboratoryで実行します。
def run_trainer(
train_file,
max_epochs=100,
batch_size=128,
bin_dir='data-bin',
device='cuda:0',
force_preprocess=False):
preprocessor = Preprocessor(
train_file,
bin_dir=bin_dir,
force_preprocess=force_preprocess)
preprocessor.run()
vocab = Vocabulary.load('vocab')
print(f'Vocabulary size: {len(vocab)}')
model = LanguageModel(vocab)
print(model)
optimizer = torch.optim.Adam(model.parameters())
trainer = LanguageModelTrainer(
model,
optimizer,
bin_dir,
device,
max_epochs=max_epochs,
batch_size=batch_size)
trainer.train()
上記のプログラムを lm.py に記述し、Google Driveにアップロードします。
ただし、ColabからGoogle Driveがマウントできていて、アップロード先は、ここではja-language-modelというフォルダとします。
Colabのセルには以下を記述し、実行します。
データのダウンロードは以下の記述を実行します。
!cd drive/My Drive/ja-language-model/
!wget https://s3-ap-northeast-1.amazonaws.com/dev.tech-sketch.jp/chakki/public/ja.text8.zip
!unzip ja.text8.zip
学習には以下の記述を実行します。
import sys; sys.path.append('drive/My Drive/ja-language-model')
import lm
lm.run_trainer('drive/My Drive/ja-language-model/ja.text8')
実行すると以下のように学習が進みます。
Run trainer
epoch:0 step:200 loss:5.63 elapsed:55.05
epoch:0 step:400 loss:5.20 elapsed:110.60
epoch:0 step:600 loss:4.98 elapsed:166.52
epoch:0 step:800 loss:4.84 elapsed:223.03
epoch:0 step:1000 loss:4.73 elapsed:279.79
--------------------------------------------------
epoch:0 loss:4.70 ppl:110.11 elapsed:296.12
Sampled: なお 「 」 「 私 」 と 述べ て いる 。 この よう な もの で ある 。 この よう な もの で ある 。 この よう な もの で ある 。 この よう な もの で ある 。 この よう な もの で ある 。 この よう な もの で ある 。 この よう な もの で ある 。 この よう な もの で ある 。 この よう な もの で ある 。 この よう な もの で ある 。 この よう な もの で ある 。 この よう な もの で ある 。 この よう な もの で ある
--------------------------------------------------
epoch:1 step:200 loss:4.15 elapsed:353.53
epoch:1 step:400 loss:4.11 elapsed:410.61
epoch:1 step:600 loss:4.08 elapsed:467.49
epoch:1 step:800 loss:4.05 elapsed:524.66
epoch:1 step:1000 loss:4.02 elapsed:581.87
--------------------------------------------------
epoch:1 loss:4.01 ppl:55.29 elapsed:598.35
Sampled: タックル ., 市 うがっ ) が 、 この よう な もの で ある 。 この よう な もの は 、 「 私 の 中 で は ない 」 と 述べ て いる 。 また 、 「 私 は 、 「 私 の 」 と 述べ て いる 。 また 、 「 私 は 、 「 私 の 」 と 述べ て いる 。 また 、 「 私 は 、 「 私 の 」 と 述べ て いる 。 また 、 「 私 は 、 「 私 の 」 と 述べ て いる 。 また 、 「 私 は 、 「 私
--------------------------------------------------
...
epoch:14 step:200 loss:3.31 elapsed:4317.59
epoch:14 step:400 loss:3.31 elapsed:4375.43
epoch:14 step:600 loss:3.31 elapsed:4433.01
epoch:14 step:800 loss:3.30 elapsed:4490.79
epoch:14 step:1000 loss:3.30 elapsed:4548.64
--------------------------------------------------
epoch:14 loss:3.30 ppl:27.20 elapsed:4565.25
Sampled: 事項 公卿 導い 重ねる 後 休 号 ( 明治 元年 ) に は 、 「 第 二 次 世界 大戦 の 第 二 次 世界 大戦 の 第 二 次 世界 大戦 の 第 二 次 世界 大戦 の 第 二 次 世界 大戦 の 第 二 次 世界 大戦 の 終戦 後 、 陸軍 士官 学校 ( 現 ・ 海軍 ) の 前身 ) に 入隊 し た 。 1945 年 ( 昭和 20 年 ) 、 第 二 次 世界 大戦 の 終戦 により 、 1945 年 ( 昭和 20 年 ) に は 陸軍 航空 隊 ( 現
--------------------------------------------------
規模が大きいデータで時間をかけた学習を実施していないため、生成されるテキストはまだ自然ではありませんが、言語モデルの評価尺度のひとつであるperplexityが少しずつ低下しているのがわかります。
おわり
本記事ではLSTMに基づく言語モデルの概要およびその学習方法のひとつであるTruncated Backpropagation Through Timeをコード付きで説明しました。 日本語のテキストを用いてColab上で学習し、生成結果を確認しました。
本記事で掲載したプログラムはここにアップロードしてあります。

つくりながら学ぶ!PyTorchによる発展ディープラーニング/小川雄太郎【3000円以上送料無料】