【自然言語処理】Scheduled samplingによるニューラル言語モデルの学習
ニューラル言語モデルはこれまでのn-gram言語モデルと比較して流暢なテキストを生成することができます。 ニューラル言語モデルの学習にはTeacher-forcingという方法がよく用いられます。 この手法はニューラル言語モデルの学習がしやすい一方で、テキスト生成時の挙動と乖離があります。 本記事では、Teacher-forcingを説明するとともに、この手法の課題を改善するための手法であるScheduled samplingを紹介します。
目次
言語モデル
ニューラル言語モデル (本記事ではニューラルネットワークにLSTMを使うものとします。また以降ニューラル言語モデルを言語モデルと呼びます) は以下の図のように直前の時刻に出力した単語や過去の文脈情報を手がかりに、現在の時刻の単語を出力する処理を繰り返して、テキストを生成できます。 各時刻において単語を出力する際は、語彙 (単語の集合) の各単語に対して生成確率を計算し、最大となる単語を選択します1。
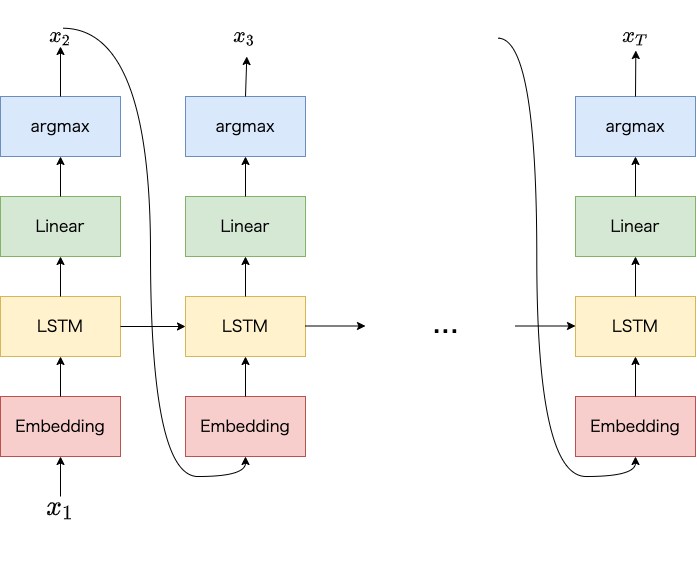 言語モデルによるテキスト生成。直前の時刻の生成確率が最大の単語を現在の時刻の入力にします。
言語モデルによるテキスト生成。直前の時刻の生成確率が最大の単語を現在の時刻の入力にします。
言語モデルの学習
本記事ではTeacher-forcingとScheduled samplingという学習方法を紹介します。
Teacher-forcing
Teacher-forcingとは
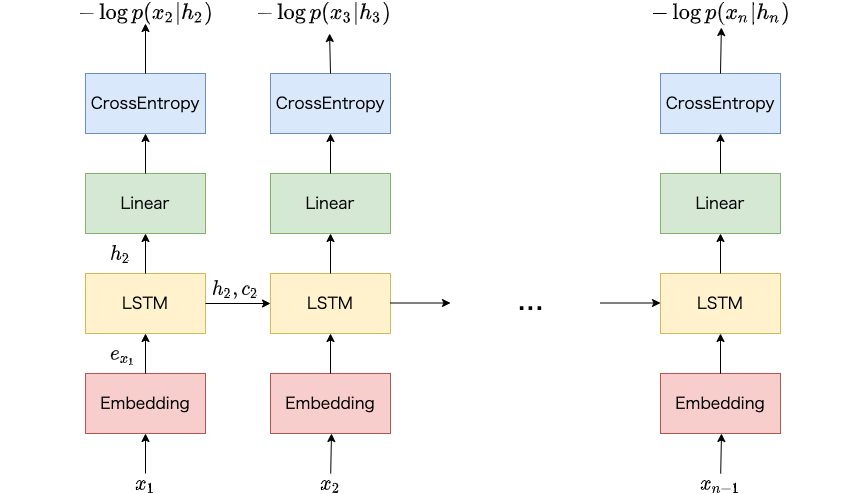
Teacher-forcingは直前の時刻の正解の単語を現在の時刻の入力とする方法です。 以下の図では学習データとしてn個の単語からなる単語列 $(x_1, …, x_n)$ が与えられています。 時刻$t$における損失を計算する際は、$x_{t-1}$を言語モデルへ入力します。 たとえば時刻$2$における損失を計算する際は、時刻$1$における単語$x_1$を入力とします。
直前の時刻における単語の生成確率は関係なく、常に直前の時刻の正解の単語を入力として、現在の時刻の単語の生成確率を計算するため、word-level trainingと呼ばれることもあります2。
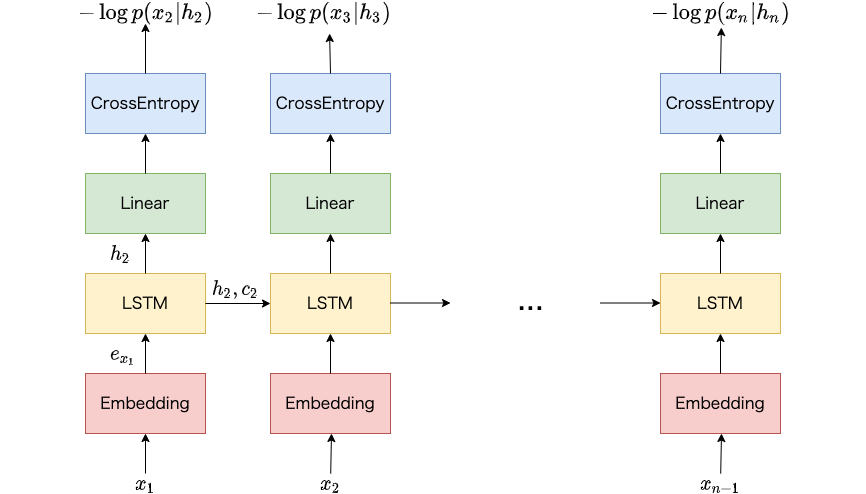 Teacher-forcing。入力となる単語は直前の時刻の正解の単語です。
Teacher-forcing。入力となる単語は直前の時刻の正解の単語です。
ニューラル言語モデルによるテキスト生成は、直前の時刻に出力した単語を用います。 学習の初期の段階ではニューラル言語モデルは、でたらめに単語を生成することが少なくありません。 でたらめな単語を入力して、現在の時刻の正解の単語を予測するのは難しいため、学習がうまく進みません。 一方で、Teacher-forcingを使って常に直前の時刻の正解の単語を入力とすることで現在の時刻の単語の予測が容易となり、学習が早く進むことが期待されます。
Teacher-forcingの課題
Teacher-forcingで言語モデルを学習することで、実際にテキストを生成する際の挙動と乖離が生まれます。 テキストを生成する際は、実際に直前の時刻に生成確率が最大となった単語を現在の時刻の入力とする一方で、Teacher-forcingでは直前の時刻の正解の単語が入力となるためです。
Teacher-forcingによって学習されたモデルは、テキスト生成時に与えられる入力は常に正しいという仮定で単語の生成を繰り返します (そういった設定で学習しているため)。 そのため、一度おかしな単語を出力してしまうと、そこからどんどんおかしな単語を繰り返し出力して最終的に生成されたテキストはおかしなものになる恐れがあります。
Scheduled sampling
Scheduled samplingとは
上記のTeacher-forcingの課題を改善するために利用されるのがScheduled samplingです。 Scheduled samplingによる学習では、常に直前の時刻の正解の単語を入力とするのではなく、直前の時刻の正解の単語と、生成確率が最大となった単語のどちらかを確率的にサンプリングして入力とします。
サンプリングの一つとして、学習が進むほど、生成確率が最大となった単語をサンプリングしやすくする方法が使われます3。学習の初期の段階では生成確率はうまく予測できないことが多いため、最初はTeacher-forcingによる学習を優先し、徐々にテキストを生成するときと同様の状況で学習するようにします。 そのため、Teacher-forcingと比較して、実際のテキスト生成時と近い状況での学習ができます。
 Scheduled sampling。入力として使われる単語は直前の時刻の正解の単語か、生成確率が最大となる単語から確率的にサンプリングされます。WとbはLinear層のパラメータを表します。
Scheduled sampling。入力として使われる単語は直前の時刻の正解の単語か、生成確率が最大となる単語から確率的にサンプリングされます。WとbはLinear層のパラメータを表します。
Scheduled samplingの課題
Scheduled samplingの課題の一つは学習時の並列化が難しいという点です。 入力となる単語は、直前の時刻の単語の生成確率が計算されていないと決められないためです。 自然言語処理でよく用いられるTransformerはTeacher-forcingであれば時間方向に対して並列に損失の計算がが可能なため、高速な学習が期待されます。 しかしながら、TransformerをScheduled samplingで学習する場合は先頭から逐次的に損失を計算しなければなりません4。
おわり
本記事ではニューラル言語モデルの学習でよく用いられるTeacher-forcing、またTeacher-forcingの課題を改善するための手法であるScheduled samplingを紹介しました。 Teacher-forcingは学習がうまく進む一方で、テキスト生成時との入力 (Teacher-forcingは直前の時刻の正解の単語、生成時は直前の時刻に出力した単語が入力) が異なります。 Scheduled samplingでは学習が進むにつれて、直前の時刻に出力した単語を入力として利用するようにします。 次回以降の記事で、実際にTeacher-forcingとScheduled samplingの比較実験をしようと思います。
-
生成確率が最大となる単語を選択する際は、softmax関数で生成確率を計算利用しなくても良いです。 ↩︎
-
Bridging the Gap between Training and Inference for Neural Machine Translation ↩︎
-
具体的なサンプリング方法は他の記事で紹介しようと思います。 ↩︎
-
Transformerなどのモデルに対しても効率的にScheduled samplingを適用する手法もあります。Parallel Scheduled Sampling ↩︎