
【無料でデータ収集】Herokuで収集したツイートをスプレッドシートに蓄積する
Twitterに日々投稿されるツイートを分析することで、今話題の情報など有用な知見を得ることができます。 日々投稿されるツイートを分析するには、定期的にツイートを収集し、蓄積する基盤が必要です。 特に個人開発においてはツイートを収集・蓄積する基盤にかかる初期費用・運用費用を可能な限り抑えたいです。 本記事では、無料で定期的にツイートを収集、蓄積するための手順をまとめました。 具体的にはHerokuとスプレッドシートを使ってTwitterから定期的に収集したツイートを蓄積するための手順を紹介します。
目次
概要
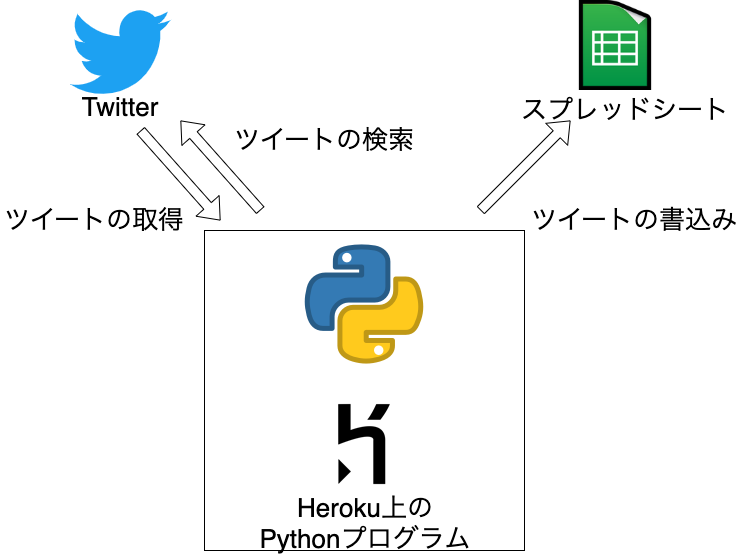 本記事で説明するプログラムの概要図。Heroku上にデプロイしたPythonプログラムが定期的にTwitterからツイートを収集し、スプレッドシートに書込みます。
本記事で説明するプログラムの概要図。Heroku上にデプロイしたPythonプログラムが定期的にTwitterからツイートを収集し、スプレッドシートに書込みます。
本記事で紹介するデータ収集基盤の概要図です。データ収集基盤はHerokuにデプロイしたPythonプログラムが、定期的にTwitterからツイートを取得し、スプレッドシートに書込みます。
Herokuはアプリケーションの開発、運用を実行するためのプラットフォームです。AWSなどでも代替できますが、サーバの設定からデプロイまでの手順が容易そうなことからHerokuを選択しました。 スプレッドシートはエクセルのような表計算アプリケーションです。無料でクラウド上にデータを保存でき、Pythonからの書込みも容易そうであることから選択しました。
このデータ収集基盤を運用する上で、Heroku、スプレッドシートAPI、Twitter APIと3つのサービスの設定が事前に必要です。 これらの設定は他の記事でも丁寧に紹介されていますので、本記事では詳細は割愛します。 設定について参考となる記事を紹介した後、収集・書込み用のプログラムと定期実行の方法を紹介します。
スプレッドシートAPIの利用準備
以下の通り利用申請を進めて、json形式のAPIキーを取得します。
【もう迷わない】Pythonでスプレッドシートに読み書きする初期設定まとめ
また、書込む対象となるスプレッドシートを作成しておきます。
作成したスプレッドシートのキーをメモしておきます。
キーはURLの<キー>の部分です。
https://docs.google.com/spreadsheets/d/<キー>/edit#gid=0
Twitter APIの利用準備
以下の通り利用申請を進めて、APIキーを取得します。
2020年度版 Twitter API利用申請の例文からAPIキーの取得まで詳しく解説
Herokuの利用準備
以下のチュートリアルの通り実行して、Herokuにアプリを作成します。
Getting Started on Heroku with Python
ツイートを収集しスプレッドシートへ書き込むプログラム
本記事ではPython 3.7.3を用います。
また必要なライブラリは以下のようにしてください。
pip install gspread==3.6.0
pip install oauth2client==4.1.3
pip install requests==2.23.0
pip install requests_oauthlib==1.3.0
インストールしたライブラリは以下のようにimportします。
import gspread
from oauth2client.service_account import ServiceAccountCredentials
import requests
from requests_oauthlib import OAuth1Session
スプレッドシートAPIおよびTwitter APIの認証部分は以下のように記述します。
# 設定ファイルの読み込み
config = configparser.ConfigParser()
config.read(config_file)
# スプレッドシートAPIの設定
scope = ['https://spreadsheets.google.com/feeds','https://www.googleapis.com/auth/drive']
credentials = ServiceAccountCredentials.from_json_keyfile_name(
'<jsonファイル>',
scope)
gc = gspread.authorize(credentials)
spreadsheet_key = config['spreadsheet']['spreadsheet_key']
worksheet = gc.open_by_key(spreadsheet_key).sheet1
# Twitter APIの設定
api_key = config['twitter']['api_key']
api_secret_key = config['twitter']['api_secret_key']
access_token = config['twitter']['access_token']
access_token_secret = config['twitter']['access_token_secret']
client = OAuth1Session(
api_key,
api_secret_key,
access_token,
access_token_secret)
config_fileはtwitter、spreadsheetというセクションがあり、それぞれAPIの認証に必要な情報が記入されているファイル (config.ini) とします。
[twitter]
api_key =
api_secret_key =
access_token =
access_token_secret =
[spreadsheet]
spreadsheet_key =
また<jsonファイル>にはスプレッドシートのjson形式のAPIキーを指定します。
実際の収集は以下のように記述します。ここでdump関数は与えられたワークシートにTwitter APIから取得したデータを書き込む関数です。
url = 'https://api.twitter.com/1.1/search/tweets.json'
max_id = -1
params = {
'q': '<検索クエリ>',
'count': 100,
'max_id': max_id,
'tweet_mode': 'extended',
'lang': 'ja',
}
while True:
try:
res = client.get(url, params=params)
except Exception as e:
logger.error(e)
continue
if res.status_code == 200:
data_i = json.loads(res.text)
if len(data_i['statuses']) > 0:
dump(worksheet, data_i['statuses'])
min_id_i = min(d['id'] for d in data_i['statuses'])
# 最新のTweetの上限を更新
params['max_id'] = min_id_i - 1
max_id_i = max(d['id'] for d in data_i['statuses'])
if max_id_i > max_id:
# 一番古いTweetの制約を更新
max_id = max_id_i
if res.status_code == 429:
break
<検索クエリ>には収集したい単語を指定します。
日本語のツイートを収集したいのでlangにはjaを指定します。
140字以上のツイートが省略されないようにtweet_modeにはextendedを指定します1。
Twitter APIの利用制限内でツイートの取得を繰り返し、制限になったらプログラムを終了します。
検索APIの詳細な仕様は公式ドキュメントを参照してください。
dump関数は以下のとおりです。
def dump(worksheet, data):
dump_data = [['', tweet['full_text']] for tweet in data]
for split in range(0, len(dump_data), 100):
start = split * 100
end = min((split + 1) * 100, len(dump_data))
worksheet.insert_rows(dump_data[start: end])
time.sleep(100)
この関数ではワークシートの先頭の行に対して新しく取得したツイートの本文をB列に書込みます。 スプレッドシートはデフォルトでは100秒に100件までしか書き込めないように制限されているため、100件書き込んだら100秒スリープします。
ローカル環境で上記プログラムを実行してスプレッドシートにツイートが書き込まれることを確認します。
Herokuへのデプロイ
プログラムが動作することを確認したら、Herokuへデプロイします。
上記プログラムをcrawler.pyとします。
requirements.txtには以下を追記してください。
gspread==3.6.0
oauth2client==4.1.3
requests==2.23.0
requests_oauthlib==1.3.0
デプロイするには以下の通り実行します。
git add crawler.py config.ini <jsonファイル> requirements.txt
git commit -m "Add crawler.py"
git push heroku master
定期収集の設定
まずプログラムを定期実行するためのアドオンである、Heroku Schedulerをインストールします。 以下のように実行します2。
cd アプリのルートディレクトリ
heroku addons:create scheduler:standard
次にHeroku Schedulerの設定ページに移動します。
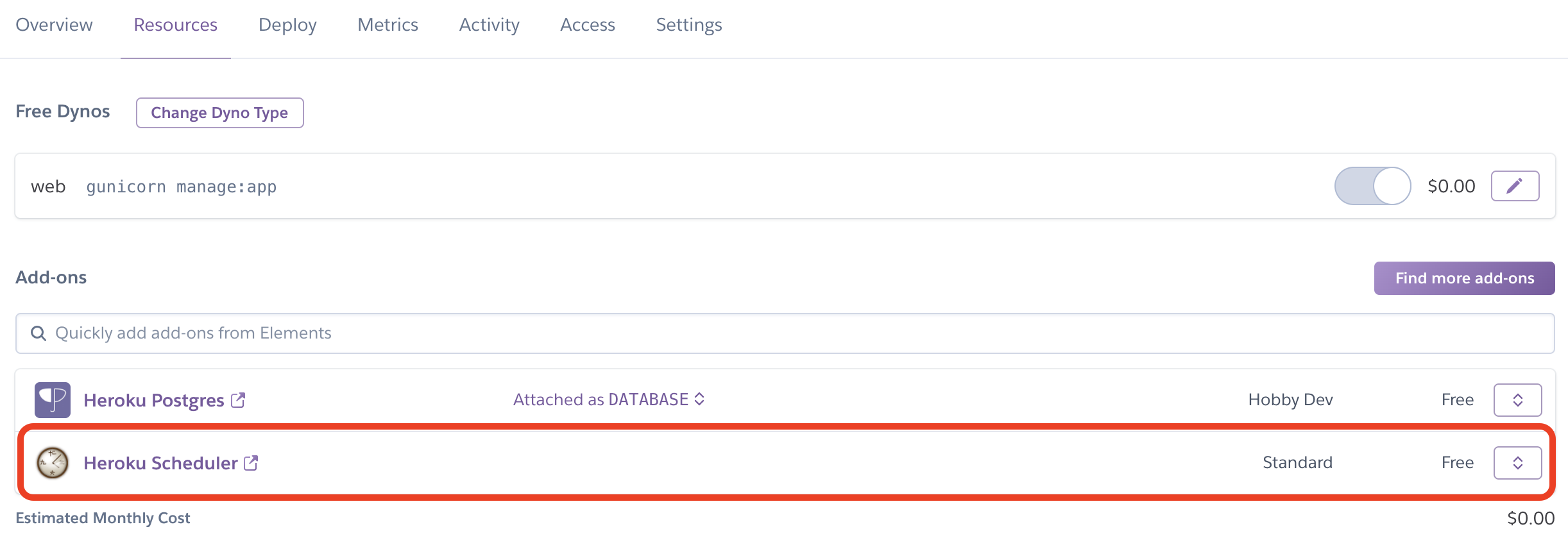 アプリのResourcesページからHeroku Schedulerをクリックします
アプリのResourcesページからHeroku Schedulerをクリックします
次に定期実行するためのジョブを追加します。
 Add jobをクリックします
Add jobをクリックします
このページを開いたら必要な情報を入力します。
 定期実行の設定を入力します
定期実行の設定を入力します
たとえばEvery hour at... :00と指定すれば、毎時0分に実行するように設定されます。
Run Commandにはpython crawler.pyと記入します。
これで一時間ごとにTwitterからツイートを取得し、スプレッドシートに書き込む環境が作成できました。
以上の通り、設定がうまくできていれば、指定したスプレッドシートに収集したツイートが書き込まれるようになります。
 収集結果
収集結果
おわり
本記事では無料でデータ収集をするための基盤を構築する方法を紹介しました。 基盤はTwitterからツイートを取得し、スプレッドシートに書き込むプログラムをHeroku上で定期実行するものです。
-
https://developer.twitter.com/en/docs/tweets/tweet-updates ↩︎
-
料金はかかりませんがアドオンの利用にはクレジットカード情報の登録が必要です。 ↩︎





