【自然言語処理】高速なニューラル機械翻訳実装CTranslate2【論文紹介】
本記事ではWNGT 2020のefficiencyシェアドタスクに提出されたEfficient and High-Quality Neural Machine Translation with OpenNMTを紹介します。 このタスクでは精度だけではなく、省メモリ、高速であることに焦点を当てています。 自然言語処理タスクの多くはニューラルネットワークに基づく巨大なモデルによって最高精度が塗り替えられていますが、実用上は精度以外にもメモリや速度の観点を検討しなければならない場面が多く、現実に即したタスクとなっています。 紹介する論文では機械翻訳で実験を行っていますが、その他のタスクに対しても適用できそうなテクニックが多く、勉強になりそうだったので紹介することにしました。 このタスクに参加した他のシステムも精度や速度などの指標においてパレート曲線状にあり、それぞれのシステムが重きをおいた指標が異なっています。 本記事で紹介する論文は速度、省メモリに焦点を当てています。
目次
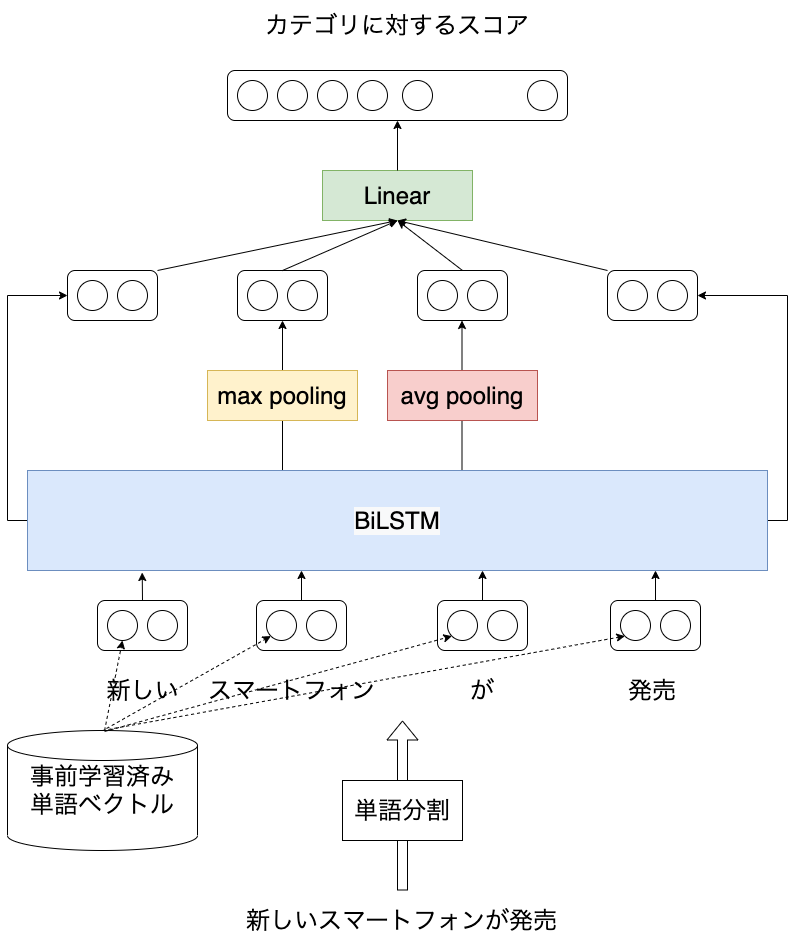
紹介する論文はTransformerを用いて機械翻訳モデルを構築しています。 以降で、コンパクトなモデルの学習方法、高速な生成の方法を紹介します。
Knowledge distillationによる小さなモデルの学習
Knowledge distillationによる学習ではKimとRush, 2016の系列生成モデルに対する蒸留手法を適用しています。 具体的にはTeacherモデルがビームサーチによって生成した単語列に対して、Studentモデルがその生成確率を最大化するような学習をおこないます。
Teacherモデル
Ngら, 2019のbig 1Transformerに基づく機械翻訳モデルをTeacherモデルとして利用しています。 モデルは学習が終了する直前の10回で保存した重みの平均としてアンサンブル化しています。
学習データ
Studentモデルの学習にはWMT 2019のタスクオーガナイザから提供された翻訳対コーパス、単言語コーパスを用いています。 学習データを自動作成する際には、ルールや言語判定を用いてデータをフィルタリングした上でTeacherモデルによって逆翻訳しています。 このようにして作成した擬似的な学習データを含めてStudentモデルの学習に用いています。
Studentモデル
Studentモデルにはbase 1Transformerに加えて、パラメータ数を減らした3種類のTransformerを採用しています。 エンコーダの層数やデコーダの層数などの設定を変えています。 原言語、目的言語のEmbeddingおよびsoftmax層の重みを共有してパラメータ数を削減しています。
Studentモデルの学習
自動作成した学習データは量が多いため、各エポックで500万事例を自動作成した学習データからランダムに選択して学習に用いています。
StudentモデルのBLEU比較
Table 3にてStudentモデルのBLEU値 (機械翻訳の自動評価尺度) を比較しています。 newstest2019というデータセットでは、FacebookがWMT 2019に提出したモデル (Studentモデルの学習に用いたTeacherモデル) よりも高いBLEU値となっているStudentモデルもありました。 このようにStudentモデルがTeacherモデルよりも高い性能を示すという報告は他の論文でもあり、今回の実験結果からも同じことが言えることがわかります。
生成の高速化
学習ではOpenNMT-tfを用いていますが、生成にはTransformerに主な焦点を当てたC++実装 (CTranslate2) を用いています。
CTranslate2の概要
- CPUとGPUをサポートし、高速、軽量であることが主な焦点
- 量子化、並列処理、外部からのメモリ要求に対応、翻訳結果の一部を外部から指定可能
- CPU実行環境ではInterlのプロセッサに最適化された数値演算ライブラリのMKLを用いている
- GPU実行環境ではcuBLAS、Thrustを用いている
8-bit量子化
学習が終了した後、Embeddingのパラメータ、線形変換の重み ($\mathbf{W}$) を符号付き8bitに変換しています。 学習の段階で量子化はせず、生成時に量子化するだけで、精度を低下させることなく生成速度を高速化できることを確認しています。 線形変換の量子化は動的量子化を採用しており、$\mathbf{y} = \mathbf{W}\mathbf{x} + \mathbf{b}$を計算する際に、$\mathbf{W}\mathbf{x}$は8bitで計算し、$+\mathbf{b}$する際にfloatに戻して足し合わせています。
線形変換の重み$\mathbf{W}$は、モデル読み込み時にpacked形式2 (int8で$\mathbf{W}\mathbf{x}$を計算するときの$\mathbf{W}$の内部形式) に変換しておくことで、入力$\mathbf{x}$が与えられたときに毎回packed形式に変換せずに済むようにしています。
Greedy decoding
生成時の高速化のため、beam searchではなくgreedy searchを用いています。 またsoftmax層では確率として正規化する前の値に対してargmaxを適用し、値が最大となる単語を出力しています3。
線形変換の結果のキャッシュ
Transformerデコーダのself-attention計算において、key、value (これまでに出力した単語列から得られる情報) の線形変換は毎回同じ計算結果になるため、キャッシュしておくことで冗長な計算を削減しています。 同様にencoder-decoder-attentionの計算において、key、value (原言語の単語列から得られる情報) の線形変換は毎回同じ計算結果になるため、同様にキャッシュしています。
系列長でソートしてミニバッチ作成
複数の事例に対して翻訳を生成する際、データをミニバッチ化します。 ミニバッチ内の系列長がばらばらだと、パディングの数が増え、不要な計算が増えます。 できるだけパディングを少なくするため、事前に事例を系列長でソートし、系列長が近い事例が同じミニバッチになるようにします。
動的な語彙削減
語彙サイズが大きいと、softmax層の計算に時間がかかるため、原言語の入力文関連する単語集合からなる小さな語彙を作成しています。
実験結果
Table 5に上記テクニックによる効果が示されています。 base 1TransformerをシングルCPUコア上でCTranslate2および上記テクニックを使って実行すると、OpenNMT-tfを使って実行するよりも8倍の高速化が確認できます。
またTable 6にOpenNMT-tfを実装としてビームサーチによって生成した結果をベースラインとして比較結果を示しています。 CPUではベースラインと比較して0.8ポイントのBLEU値低下ではあるものの、13倍の高速化が確認できます。 GPUではベースラインとしてBLEU値を低下させずに、8倍の高速化が確認できます。
おわり
本記事ではニューラルネットワークに基づく機械翻訳モデルを精度を落とさずに高速化するための方法について紹介しました。
-
モデルの設定は https://arxiv.org/pdf/1706.03762.pdf のTable 3を参照してください ↩︎
-
https://techdecoded.intel.io/resources/reducing-packing-overhead-in-matrix-matrix-multiplication/ ↩︎
-
softmax関数は単調増加関数で、入力と出力の大小関係は変わらないため、argmaxの結果は変わりません。 ↩︎