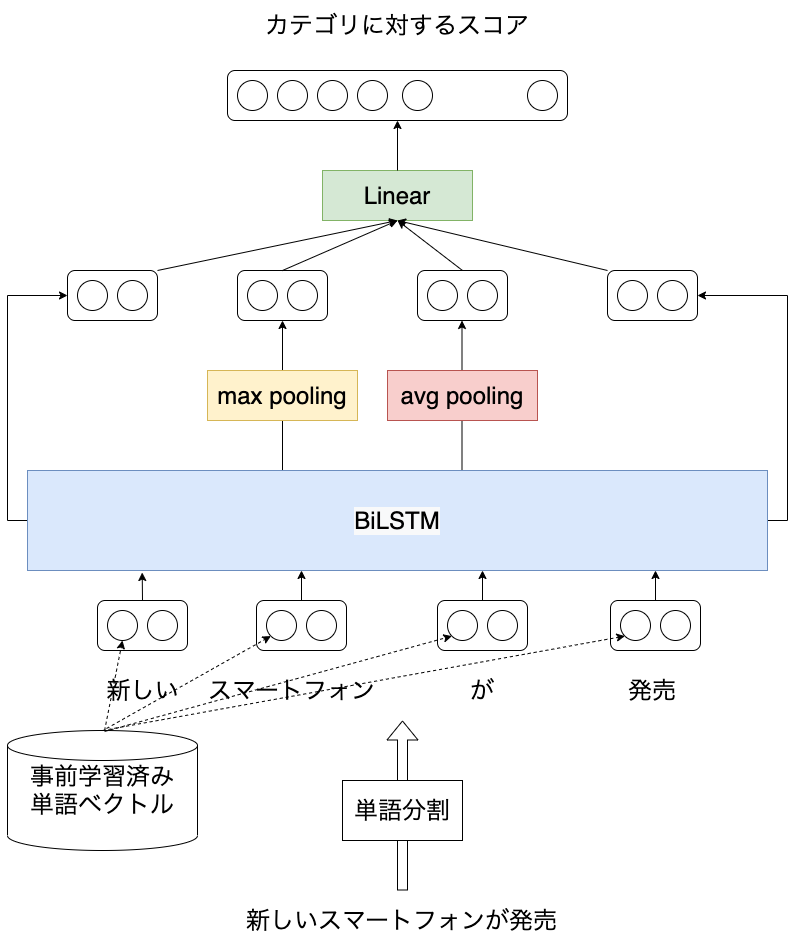
本記事では日本語を対象としたLSTMに基づく文書分類モデルをPyTorchコード付きで紹介します。 以前、LSTMを用いた言語モデルについて紹介しました ( [自然言語処理] LSTMに基づく言語モデルの学習 (PyTorchコード付き) ) が、ニューラルネットワークを用いた自然言語処理の応用例として文書分類のほうがイメージしやすそうなので、こちらについても紹介したいと思います。 実験にはライブドアコーパスから作成した、記事の見出しに対して9つのカテゴリのうち、どれか1つが付与されたデータを使います。 本記事を読むことで日本語を対象に、ニューラルネットワークを活用した自然言語処理の概要を知ることができます。 また、PyTorchで事前学習済みの単語分散表現を扱う方法も紹介しています。
本記事では画像認識系の国際会議 ECCV2020のチュートリアルでNVIDIAが発表した資料 PYTORCH PERFORMANCE TUNING GUIDE の内容をまとめるとともに、理解の助けになるような関連情報を参照します。 PyTorchは簡単にニューラルネットワークの実装のを容易さだけでなく、処理速度にも注意を払って開発が進められています。 プログラムにほんの少し修正を加えるだけで高速化できる可能性があります。 本記事を読み、実践することで、手元のPyTorchプログラム (特にGPUを使った学習処理) を高速化できる可能性があります。
本記事ではPyTorchを使ったニューラルネットワークの学習において、不要な計算グラフを削除することでできるだけメモリを節約するための方法を紹介します。 本記事を読むことで、少しでもGPUメモリの不足によるout of memoryエラーを減らしたり、よりバッチサイズを大きくしたりして学習を実施できるようになります。
私は普段は企業の中でデータ分析や機械学習を扱った業務に携わっています。所属している企業はまだしも、他社の、しかも今データ分析を活用して売り上げを伸ばしているところの中を垣間見たい、という気持ちから【ワークマンは 商品を変えずに売り方を変えただけで なぜ2倍売れたのか】を読みました。 本書を読むことで、自分の強みを把握し、データを活用して効率的に新しい分野で活躍するまでを疑似体験できます。

本記事ではC++の単体テストフレームワークであるGoogle Testを、CMakeを使ってプログラムにリンクできるようにするための方法を紹介します。 Google Testを毎回手動でダウンロードするのは面倒ですが、本記事で紹介する方法ではCMake内でGoogle Testをgit submoduleで管理できます。
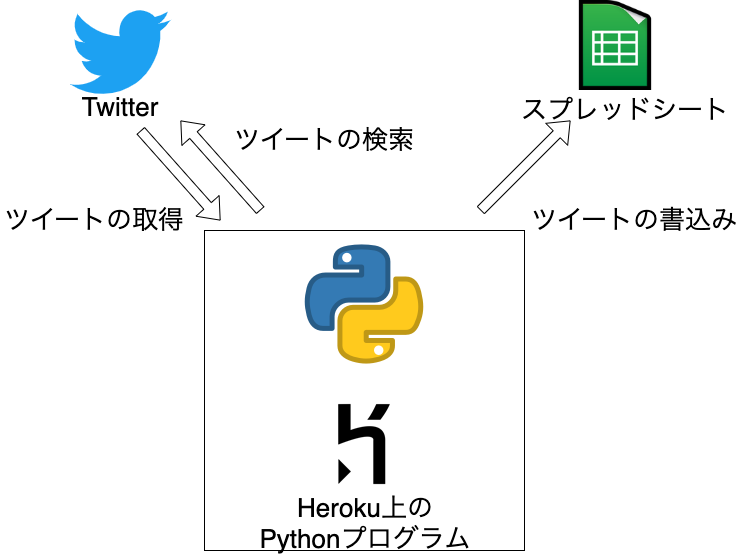
Twitterの検索APIを利用することで、Twitterに投稿されるツイートを検索し、ツイート本文、いいね数などに加えて、ツイートに添付される画像やURLなどを取得できます。 Twitterの検索APIを利用するにはAPIや得られるデータの仕様を把握しておく必要があります。 本記事では、検索APIの主な仕様およびツイートに添付されている画像データやURLなどへのアクセス方法を紹介します。