【PyTorch】不要になった計算グラフを削除してメモリを節約
本記事ではPyTorchを使ったニューラルネットワークの学習において、不要な計算グラフを削除することでできるだけメモリを節約するための方法を紹介します。 本記事を読むことで、少しでもGPUメモリの不足によるout of memoryエラーを減らしたり、よりバッチサイズを大きくしたりして学習を実施できるようになります。
目次
計算グラフ
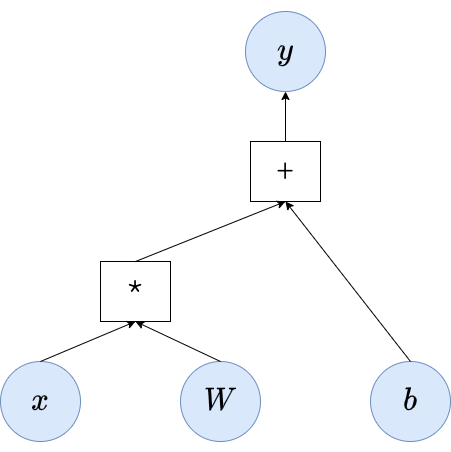 線形変換によって得られる計算グラフの例。ここでは*は行列積、+は要素和を表す関数とします。
線形変換によって得られる計算グラフの例。ここでは*は行列積、+は要素和を表す関数とします。
順伝搬処理は計算グラフを構築します。 たとえば以下の線形変換を例にします。 $$\mathbf{y}=\mathbf{W}\mathbf{x} + \mathbf{b}$$ $\mathbf{W}$と$\mathbf{b}$は線形変換のパラメータで、$\mathbf{x}$は入力とします。
上記図では$\mathbf{y}$を得るために、まず$\mathbf{W}$と$\mathbf{x}$の行列積 ($*$) を計算して、その計算結果に対して$\mathbf{b}$との要素和 ($+$) を得た結果が$\mathbf{y}$になることを表しています。
この計算グラフは誤差逆伝搬でパラメータの勾配を計算する際に用いられます。
たとえば損失関数から得られた値をEとすると、$\mathbf{W}$について勾配は以下のようになります。
$$
\begin{eqnarray}
\frac{\nabla E}{\nabla \mathbf{W}} &=& \frac{\nabla E}{\nabla \mathbf{y}} \frac{\nabla \mathbf{y}}{\nabla \mathbf{W}} \\
&=& \frac{\nabla E}{\nabla \mathbf{y}} \mathbf{x}
\end{eqnarray}
$$
このことから、$\mathbf{y}$に対する勾配と$\mathbf{x}$がわかれば、$\mathbf{W}$に対する勾配を計算できます。
計算グラフは、ノードがデータあるいは関数で、エッジが入力・出力を表すようなグラフです。 そのため、あるノードの入力となったすべてのノードを得ることができます。 たとえば、行列積 ($*$) を計算する際に利用した入力として$\mathbf{W}$と$\mathbf{x}$を取得できます。
また、出力から順に勾配を計算することで、$\mathbf{y}$に対する勾配はすでに計算されています。
これらのことから、$\mathbf{W}$に対する勾配は計算グラフを使うことで効率的に計算できます。
別の見方をすると、計算グラフは順伝搬処理で計算した中間結果を保持しています。 そのため、計算グラフを保持するための消費メモリも少なくありません。
不要な計算グラフがメモリ上に残る理由
ここからPyTorchでの話に入っていきます。
ニューラルネットワークの学習ではwhile文やfor文でミニバッチデータを取得し、損失を得るという場合があると思います。
ここでは以下のように繰り返し入力を与えて、得られた結果をlossに代入する場合を考えます。
while True:
loss = model(input)
loss.backward()
optimizer.step()
この処理でどのようなことが起きているか、細かく見ていきます。
-
1回目の順伝搬処理 (
model(input)) により、i) modelのパラメータ + ii) 損失を得るために構築された計算グラフがメモリ上に構築されます。 -
その後、1回目に構築された計算グラフは
loss = model(input)によってlossに代入されます。この計算グラフはメモリ上に存在したまま、2回目の計算グラフの構築が始まります -
誤差逆伝播 (
loss.backward()) を実行し、パラメータを更新 (optimizer.step()) します。 -
2回目の順伝搬処理、つまり
model(input)の実行後、 i) modelのパラメータ + ii) 2回目のmodel(input)で構築された計算グラフ + iii) 1回目のmodel(input)で構築された計算グラフ がメモリ上に存在します -
loss = model(input)によって、2回目の損失がlossに代入され、ここで1回目の損失を得るために構築された計算グラフは削除されます
3回目の順伝搬処理からは、3., 4., 5.の繰り返しになります。
ここで、 ステップ4において、計算グラフが2つ存在する ことになります。 計算グラフは勾配を求めるために用いるものなので、誤差逆伝播を実行した計算グラフは不要にも関わらず、メモリを消費してしまいます。
不要な計算グラフを削除してメモリを節約する
できるだけGPUの無駄なメモリ消費を減らしたい場合、以下のように1行加えるだけで不要な計算グラフを削除できます。
while True:
loss = model(input)
loss.backward()
del loss # 誤差逆伝播を実行後、計算グラフを削除
optimizer.step()
前述したように、誤差逆伝搬によりパラメータの勾配が得られたら、その計算グラフは不要になります。
上記例だとloss.backward()を実行後にdel lossとすることで、不要になった計算グラフを削除できます1。
おわり
本記事ではニューラルネットワークの学習時におけるメモリ節約のテクニックとして、不要になった計算グラフを削除する方法を紹介しました。 限られたメモリで大きなミニバッチサイズでの学習をする方法も紹介しているので、よろしければこちらも読んでみてください。
【PyTorch】限られたメモリにおける大きなバッチサイズでの学習
最後に本記事を書くにあたり参考にした記事を参照します。
Calling loss.backward() reduce memory usage?
-
Facebookが開発している系列変換のためのPyTorchライブラリ fairseq でも使われているテクニックです: https://github.com/pytorch/fairseq/commit/6b54873c417460ad1c6a10593977eba6947b0fd6 ↩︎