【自然言語処理】LSTMに基づく文書分類 (PyTorchコード付き)
本記事では日本語を対象としたLSTMに基づく文書分類モデルをPyTorchコード付きで紹介します。 以前、LSTMを用いた言語モデルについて紹介しました ( [自然言語処理] LSTMに基づく言語モデルの学習 (PyTorchコード付き) ) が、ニューラルネットワークを用いた自然言語処理の応用例として文書分類のほうがイメージしやすそうなので、こちらについても紹介したいと思います。 実験にはライブドアコーパスから作成した、記事の見出しに対して9つのカテゴリのうち、どれか1つが付与されたデータを使います。 本記事を読むことで日本語を対象に、ニューラルネットワークを活用した自然言語処理の概要を知ることができます。 また、PyTorchで事前学習済みの単語分散表現を扱う方法も紹介しています。
目次
本記事で利用するPythonモジュール
- gensim 3.8.3
- mecab-python3 0.996.1
- numpy 1.16.2
- pytorch 1.5.0
- scikit-learn 0.22.1
文書分類モデル
文書分類モデルは以下のような構成にしました。
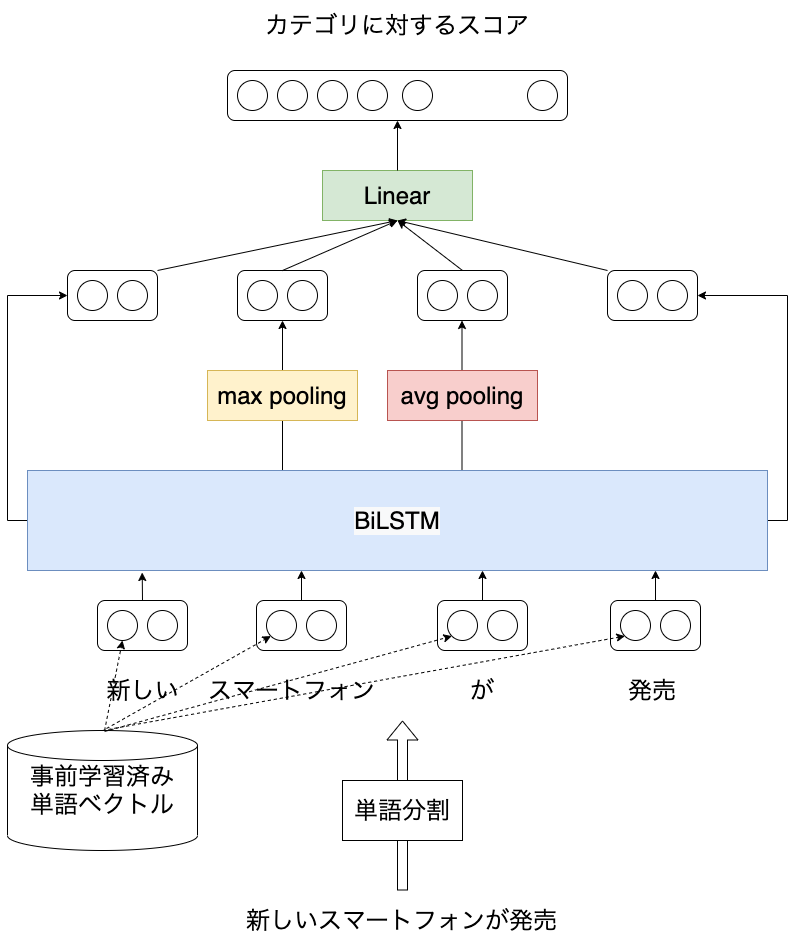 LSTMに基づく文書分類モデルの概要図
LSTMに基づく文書分類モデルの概要図
まず、入力文を単語分割します。 次に、得られた単語を二種類の分散表現へ変換します。 一つは学習対象となる分散表現で、もう一つは事前学習した分散表現とします。 事前学習した分散表現に関しては文書分類モデルの学習時は学習対象としないようにします。 得られた分散表現を入力として双方向LSTM (BiLSTM) から先頭の単語と末尾の単語に対する隠れ状態を取得します1。 また各単語に対して得られたBiLSTMの隠れ状態を対象にプーリングを適用してベクトルを取得します2。 最後に、文に対して得られた複数のベクトルの結合を入力として、文書カテゴリに対するスコアを予測します。
分散表現を学習対象のものと、事前学習済みのものに分けたのは、ライブドアコーパスから作成した学習データのサイズがそれほど大きくないため、テストデータに出現する単語を十分にカバーできない可能性があるのと、十分に分散表現を学習できない可能性があるためです。
分散表現を2つに分けることで、そのコーパスに依存した分散表現は学習しつつも、巨大なラベルなしコーパスから学習した分散表現を利用するため、精度改善が期待されます。
プーリングは画像認識における畳み込みニューラルネットワークで利用されることが多い印象を持つかもしれませんが、自然言語処理でも使われることがあります。
今回のような文書分類では、文全体の特徴に加えて、局所的な特徴 (特定の単語や句) が分類精度に寄与することが考えられます。たとえばスマートフォンという単語が出現すればIT関係のカテゴリに分類される、など。 このような局所的な特徴も考慮するために、プーリングも適用しています。
上記の図をPyTorchで実装したものが以下になります。 LSTMは学習時にWeight drop を適用しています。 Weight dropに関するモジュールはPyTorch-NLPを参考にしています。
def _weight_drop(module, weights, dropout):
for name_w in weights:
w = getattr(module, name_w)
del module._parameters[name_w]
module.register_parameter(name_w + '_raw', torch.nn.Parameter(w))
original_module_forward = module.forward
def forward(*args, **kwargs):
for name_w in weights:
raw_w = getattr(module, name_w + '_raw')
w = torch.nn.functional.dropout(raw_w, p=dropout, training=module.training)
setattr(module, name_w, w)
return original_module_forward(*args, **kwargs)
setattr(module, 'forward', forward)
class WeightDrop(torch.nn.Module):
def __init__(self, module, weights, dropout=0.0):
super(WeightDrop, self).__init__()
_weight_drop(module, weights, dropout)
self.forward = module.forward
class WeightDropLSTM(torch.nn.LSTM):
def __init__(self, *args, weight_dropout=0.0, weight_names_to_drop=[], **kwargs):
super().__init__(*args, **kwargs)
_weight_drop(self, weight_names_to_drop, weight_dropout)
def loss_fn(model, batch):
return F.nll_loss(
torch.log_softmax(model(batch), dim=-1),
batch['label']
)
class Classifier(torch.nn.Module):
def __init__(
self,
feature_vocab,
category_vocab,
embedding_size=128,
embedding_path=None,
hidden_size=256,
num_layers=1,
weight_dropout=0.1,
**kwargs,
):
super().__init__()
self.feature_vocab = feature_vocab
self.category_vocab = category_vocab
self.embedding_size = embedding_size
self.hidden_size = hidden_size
self.embedding = torch.nn.Embedding(
len(feature_vocab),
embedding_size,
padding_idx=feature_vocab.get_index('<pad>')
)
self.key_vector = None
if embedding_path:
self.key_vector = gensim.models.KeyedVectors.load(
embedding_path,
mmap='r',
)
self.num_layers = num_layers
self.weight_names_to_drop = [
f'weight_hh_l{i}' for i in range(self.num_layers)
]
self.weight_names_to_drop = [
f'weight_hh_l{i}_reverse' for i in range(self.num_layers)
]
self.bidirectional = True
self.lstm = WeightDropLSTM(
input_size=embedding_size self.key_vector.vector_size if embedding_path
else embedding_size,
hidden_size=hidden_size,
num_layers=num_layers,
bidirectional=self.bidirectional,
weight_dropout=weight_dropout,
weight_names_to_drop=self.weight_names_to_drop,
)
self.out = torch.nn.Linear(
8 * hidden_size,
len(category_vocab),
bias=True)
def static_embeedding(self, inputs):
bsz = len(inputs['raw_words'])
seq_len = 0
for batch_idx in range(len(inputs['raw_words'])):
seq_len = max(seq_len, len(inputs['raw_words'][batch_idx]))
embed = torch.zeros((bsz, seq_len, self.key_vector.vector_size))
for batch_idx in range(len(inputs['raw_words'])):
for t, word in enumerate(inputs['raw_words'][batch_idx]):
if word in self.key_vector:
embed[batch_idx, t, :] = torch.from_numpy(
np.array(self.key_vector.get_vector(word))
)
return embed
def load_state_dict(self, state_dict):
state_dict = super().load_state_dict(state_dict, strict=False)
return state_dict
def __call__(self, inputs):
x = inputs['words']
bsz, seq_len = x.size()
lengths = (x != self.feature_vocab.get_index('<pad>')).sum(dim=1)
# (bsz, seq_len, embedding_size)
x = self.embedding(x)
if self.key_vector:
static_x = self.static_embeedding(inputs).to(inputs['words'].device)
x = torch.cat([x, static_x], dim=-1)
packed = torch.nn.utils.rnn.pack_padded_sequence(
x,
lengths,
batch_first=True,
enforce_sorted=False
rnn_out, (ht, ct) = self.lstm(packed)
ht = ht.view(self.num_layers, 2, bsz, -1)
ht = ht[-1] # (2, bsz, hidden_size)
ht = (
ht.transpose(0, 1) # (bsz, 2, hidden_size)
.contiguous()
.view(bsz, 2 * self.hidden_size)
)
# (bsz, seq_len, 2 * hidden_size)
x, _ = torch.nn.utils.rnn.pad_packed_sequence(rnn_out, batch_first=True)
# (bsz, 1, 2 * hidden_size)
h_max = F.adaptive_max_pool2d(
x.view(bsz, 1, seq_len, -1),
(1, 2 * self.hidden_size)
).squeeze(1)
h_avg = F.adaptive_avg_pool2d(
x.view(bsz, 1, seq_len, -1),
(1, 2 * self.hidden_size)
).squeeze(1)
# (bsz, 4 * 2 * hidden_size)
x = torch.cat([x[:, 0], ht, h_max.squeeze(1), h_avg.squeeze(1)], dim=-1)
# (bsz, category_size)
x = self.out(x)
return x
データ前処理
この章ではライブドアコーパスを対象とした前処理部分を紹介します。
今回は、記事の見出しを入力としてその記事のカテゴリを予測したいため、read_data関数から見出しとカテゴリに相当する情報を取得します。
def read_data(data_dir):
files = glob.glob(f'{data_dir}/*/*.txt')
categories = []
titles = []
for fname in files:
elems = fname.split('/')
category = elems[-2] # ディレクトリ名をカテゴリとして取得
with open(fname) as f:
next(f)
next(f)
title = next(f).rstrip() # ファイルの3行目をタイトルとして取得
categories.append(category)
titles.append(title)
print('#Files:', len(titles))
return categories, titles
次にカテゴリと見出しを学習データ、テストデータに分割します。 その後、これらのデータに対して前処理を適用し、得られた前処理結果を保存します。
def create_dataset(args, categories, titles):
# 学習データとテストデータに分割
categories_train, categories_test, titles_train, titles_test = train_test_split(
categories,
titles,
random_state=42,
stratify=categories,
)
# 学習データとテストデータの分布を表示
dist = Counter(categories_train)
print('Training')
for k, v in sorted(dist.items(), key=lambda x: x[1], reverse=True):
print(v, k)
print()
dist = Counter(categories_test)
print('Test')
for k, v in sorted(dist.items(), key=lambda x: x[1], reverse=True):
print(v, k)
# カテゴリや単語をidに変換するクラスの作成
category_vocab = Vocabulary()
feature_vocab = Vocabulary()
feature_vocab.add_item('<s>')
feature_vocab.add_item('</s>')
feature_vocab.add_item('<unk>')
feature_vocab.add_item('<pad>')
# Create vocabularies
for category in categories_train:
if not category in category_vocab:
category_vocab.add_item(category)
tagger = MeCab.Tagger('-Owakati')
# 学習データを単語分割し、単語の頻度を取得
word_freq = Counter()
titles_tokenized_train = []
for title in titles_train:
result = tagger.parse(title).rstrip()
words = result.split()
word_freq.update(words)
titles_tokenized_train.append(words)
# 単語の頻度上位vocab_size件をvocabularyに追加
for word, freq in sorted(
word_freq.most_common(args.vocab_size),
key=lambda x: x[1],
reverse=True
):
feature_vocab.add_item(word)
unk = feature_vocab.get_index('<unk>')
def create_idx_data(cs, ts):
y = []
X = []
for category in cs:
y_i = category_vocab.get_index(category)
y.append(y_i)
for title_tokenized in ts:
x = []
for word in title_tokenized:
if word in feature_vocab:
word_idx = feature_vocab.get_index(word)
else:
word_idx = unk
x.append(word_idx)
X.append(x)
assert len(y) == len(X), f'{len(y)} != {len(x)}'
return y, X
# 学習データの単語やカテゴリ情報をidに変換する
y_train, X_train = create_idx_data(categories_train, titles_tokenized_train)
# テストデータの単語やカテゴリ情報をidに変換する
titles_tokenized_test = []
for title in titles_test:
result = tagger.parse(title).rstrip()
words = result.split()
titles_tokenized_test.append(words)
y_test, X_test = create_idx_data(categories_test, titles_tokenized_test)
print('#Train:', len(y_train), '#Test:', len(y_test))
# 単語およびカテゴリをIDに変換する・またその逆をおこなうオブジェクトを保存する
category_vocab.save('category.dict')
feature_vocab.save('feature.dict')
if args.embedding_path:
# 事前学習済み単語ベクトルが記述されたテキスト形式のファイルを読み込み、バイナリ形式で保存する
kv = gensim.models.KeyedVectors.load_word2vec_format(args.embedding_path)
kv.save('embedding.bin')
# 学習データおよびテストデータを保存する
torch.save([
{
'label': y,
'words': torch.tensor(x, dtype=torch.long),
'raw_words': z,
}
for y, x, z in zip(y_train, X_train, titles_tokenized_train)
], 'train.pt')
torch.save([
{
'label': y,
'words': torch.tensor(x, dtype=torch.long),
'raw_words': z,
}
for y, x, z in zip(y_test, X_test, titles_tokenized_test)
], 'test.pt')
def preprocess(args):
categories, titles = read_data(args.data_dir)
create_dataset(args, categories, titles)
preprocess関数を実行すると以下のような表示が得られます。
事前学習済みの分散表現はsingletongue / WikiEntVecで公開されている300次元のものを利用しました。
#Files: 7376
Training
676 sports-watch
654 dokujo-tsushin
653 it-life-hack
653 movie-enter
653 smax
649 kaden-channel
632 peachy
578 topic-news
384 livedoor-homme
Test
225 sports-watch
218 it-life-hack
218 smax
218 movie-enter
217 dokujo-tsushin
216 kaden-channel
211 peachy
193 topic-news
128 livedoor-homme
#Train: 5532 #Test: 1844
モデル学習
前処理でデータを作成したら、実際に文書分類モデルを学習します。
学習には以下のtrain関数を用います。
def collate_fn(pad):
def _collate_fn(samples):
batch = {}
for sample in sorted(samples, key=lambda x: len(x['words']), reverse=True):
for k, v in sample.items():
if not k in batch:
batch[k] = [v]
else:
batch[k].append(v)
batch['label'] = torch.tensor(batch['label'], dtype=torch.long)
batch['words'] = torch.nn.utils.rnn.pad_sequence(
batch['words'],
batch_first=True,
padding_value=pad
)
return batch
return _collate_fn
def move_to_cuda(batch, gpu):
batch['label'] = batch['label'].cuda(gpu)
batch['words'] = batch['words'].cuda(gpu)
return batch
def train(args):
# 学習時に用いたハイパーパラメータ情報を予測時に使うために保存
with open(args.param_file, 'w') as f:
param = vars(args)
del param['handler']
json.dump(param, f, indent=4)
# 単語およびカテゴリをIDに変換するオブジェクトを読み込む
feature_vocab = Vocabulary.load('feature.dict')
category_vocab = Vocabulary.load('category.dict')
# 前処理で作成した学習データを読み込む
data = torch.load('train.pt')
pad = feature_vocab.get_index('<pad>')
model = net.Classifier(
feature_vocab,
category_vocab,
embedding_size=args.embedding_size,
embedding_path=args.embedding_path,
hidden_size=args.hidden_size,
num_layers=args.num_layers,
weight_dropout=args.weight_dropout)
if args.gpu >= 0:
model.cuda(args.gpu)
print(model)
optimizer = torch.optim.AdamW(model.parameters())
print(optimizer)
model.train()
optimizer.zero_grad()
for epoch in range(args.max_epochs):
loss_epoch = 0.
step = 0
for batch in torch.utils.data.DataLoader(
data,
batch_size=args.batch_size,
shuffle=True,
collate_fn=collate_fn(pad),
):
optimizer.zero_grad()
if args.gpu >= 0:
batch = move_to_cuda(batch, args.gpu)
loss = net.loss_fn(model, batch)
loss.backward()
loss_epoch += loss.item()
del loss
torch.nn.utils.clip_grad_norm_(model.parameters(), args.clip)
optimizer.step()
step += 1
print(f'epoch:{epoch+1}: loss:{loss_epoch:.5f}')
# 学習した文書分類モデルを保存
torch.save(model.state_dict(), args.model)
del lossの説明は以下の記事を御覧ください。
【PyTorch】不要になった計算グラフを削除してメモリを節約
上記を実行すると以下のような結果が得られます。
Classifier(
(embedding): Embedding(13086, 50, padding_idx=3)
(lstm): WeightDropLSTM(350, 100, bidirectional=True)
(out): Linear(in_features=800, out_features=9, bias=True)
)
AdamW (
Parameter Group 0
amsgrad: False
betas: (0.9, 0.999)
eps: 1e-08
lr: 0.001
weight_decay: 0.01
)
epoch:1: loss:322.43662
epoch:2: loss:144.89778
epoch:3: loss:87.69048
epoch:4: loss:50.57606
epoch:5: loss:27.93044
本記事ではGoogle ColabのGPUを使って実験を実施しました。 Google Colabがわからない方、利用するための準備がわからない方は以下の記事を御覧ください。
[Colab] Googleの無料GPU環境を使うための準備
評価
最後に学習済み文書分類モデルをテストデータを使って評価します。
def evaluate(args):
feature_vocab = Vocabulary.load('feature.dict')
category_vocab = Vocabulary.load('category.dict')
# 学習時に保存したハイパーパラメータを読み込む
with open(args.param_file, 'r') as f:
params = json.load(f)
model = net.Classifier(
feature_vocab,
category_vocab,
**params)
# 学習済みパラメータを読み込む
model.load_state_dict(torch.load(args.model))
if args.gpu >= 0:
model = model.cuda(args.gpu)
# 前処理で作成したテストデータを読み込む
test_data = torch.load('test.pt')
predictions = []
targets = []
model.eval()
pad = feature_vocab.get_index('<pad>')
match = 0
with torch.no_grad():
for batch in torch.utils.data.DataLoader(
test_data,
batch_size=args.batch_size,
shuffle=False,
collate_fn=collate_fn(pad),
):
if args.gpu >= 0:
batch = move_to_cuda(batch, args.gpu)
pred = torch.argmax(model(batch), dim=-1)
target = batch['label']
match += (pred == target).sum().item()
predictions.extend(pred.tolist())
targets.extend(target.tolist())
acc = match / len(targets)
prec, rec, fscore, _ = precision_recall_fscore_support(predictions, targets)
print('Acc', acc)
print('===')
print('Category', 'Precision', 'Recall', 'Fscore', sep='\t')
for idx in range(len(category_vocab)):
print(f'{category_vocab.get_item(idx)}\t'
f'{prec[idx]:.2f}\t{rec[idx]:.2f}\t{fscore[idx]:.2f}')
prec, rec, fscore, _ = precision_recall_fscore_support(predictions, targets, average='micro')
print(f'Total\t{prec:.2f}\t{rec:.2f}\t{fscore:.2f}')
以下のような結果が得られました。
Acc 0.8432754880694143
===
Category Precision Recall Fscore
kaden-channel 0.93 0.92 0.93
dokujo-tsushin 0.88 0.80 0.84
it-life-hack 0.87 0.88 0.88
movie-enter 0.73 0.93 0.82
topic-news 0.94 0.68 0.79
livedoor-homme 0.71 0.75 0.73
sports-watch 0.84 0.95 0.89
smax 0.96 0.93 0.95
peachy 0.68 0.76 0.72
Total 0.84 0.84 0.84
F値で84%程度となっています3。 以前書いた記事は単語のtfidfを素性としたパーセプトロンをライブドアコーパスの見出し分類を紹介しました。 パーセプトロンでは約70%程度だったので、それと比較すると高い値となっています。ただし、学習データとテストデータの分割が違うので厳密には比較にはなりません。
[Python] scikit-learnで学ぶパーセプトロンによる文書分類入門
おわり
本記事ではLSTMに基づく文書分類モデルをPyTorchコード付きで紹介しました。 また今回記載したプログラムはtma15 / pytorch-lstm-document-classificationにアップロードしてありますので、よければ参考にしてください。
-
BiLSTMは文の先頭から末尾に処理するLSTMと末尾から先頭に処理するLSTMの2つからなります。先頭の単語の隠れ状態は、2つのLSTMの隠れ状態の結合です。片方の隠れ状態は末尾から計算した文脈情報が含まれているため、文の情報を含んでいると考えられます。 ↩︎
-
LSTM部分についてはUniversal Language Model Fine-tuning for Text Classificationを参考にしました。 ↩︎
-
事前学習済み分散表現を使わないと、F値は72%程度でした。このことから事前学習済み分散表現を活用して未知語を減らすことが分類精度に寄与しているといえます。またプーリングを使わない場合ではF値は殆ど変わりませんでした。これは、分類対象が見出しであり、比較的単語数が少ないテキストであったため、分類精度にあまり寄与しなかった可能性があります。またweight dropも分類精度にあまり影響しませんでした。こちらも対象とするテキストが比較的短かったことが影響するかもしれません。 ↩︎