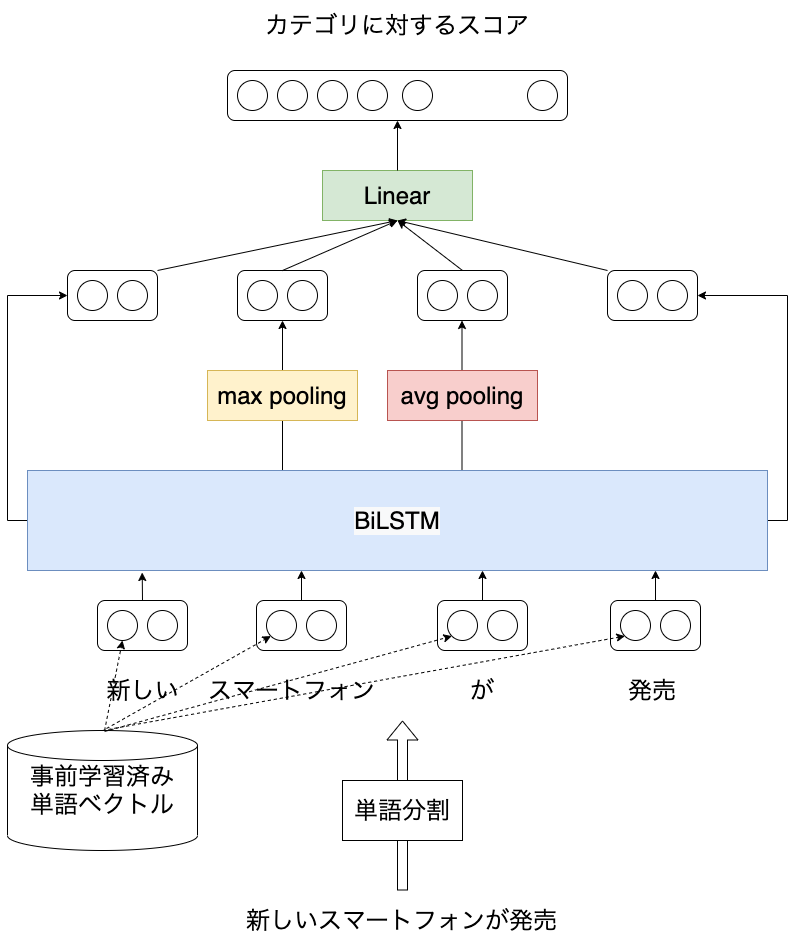
【機械学習】学習データ作成作業を効率化する能動学習OSSまとめ
本記事では機械学習モデルを効率的に構築するためのアプローチのひとつである、能動学習を利用可能なOSSについて調査し、その概要をまとめます。 機械学習を活用するときは、モデルを構築するために必要な学習データをどのように作成するかという点を検討しなければなりません。 コンペなどで利用されるベンチマークデータでは規模の大きな学習データが用意されていますが、自分のプロジェクトで機械学習を利用するために必要な学習データがすでに揃っているというケースはあまり多くありません。 効率的に学習データを作成するための手法として、能動学習というものがあります。 能動学習は、予め学習済みの機械学習モデルが予測結果に自信のない事例に対して、人の作業者にラベル付を依頼し、新しく作成された学習データでモデルを再学習するような処理の流れになります。 やみくもに事例にラベルをつけるのではなく、現在のモデルが失敗しやすい事例に対してラベルを付与するため、効率的な学習データの構築が期待できます。 本記事を読むことで、状況に合わせたOSSの選定に役立てられます。
目次
はじめ
機械学習はモデルを構築するために学習データ(正解ラベルが付いた事例)を必要とします。 特に個人開発における機械学習モデルの構築では、正解ラベルを付けるアノテーション作業を人にお願いする予算もないため、クラウドソーシングなどを活用した複数人でのアノテーションは難しいです。
アノテーションは、良いモデルを構築する上で非常に重要な作業になります。高品質なアノテーションを効率的に進めていく上で考えなければいけないことはいくつもあると思いますが、ここでは2つの懸念事項を挙げます。
- アノテータを雇って学習データを構築することが難しい(という状況を考えています)ので大量のデータに対して人手でラベルをつけるのは大変です。
- 機械学習は、与えられた学習データに対して正解ラベルを予測できるようにモデルを学習します。そのため、すでにモデルが正しくラベルを予測できるような事例に対して新しく正解ラベルを付けても、傾向の異なる未知の事例に対して正しく予測をすることができない可能性が高いです。
これらのことから、できるだけ少量の学習データで、かつモデルが苦手とするような学習事例を効率的に集める方法を検討したいです。
学習データの作成にかかる負担を減らすアプローチとして、能動学習というものがあります。 能動学習では、何らかの機械学習モデルが、未知の事例に対して、正解ラベルを付与するように人間に問い合わせるようなインタラクションをおこないます。
たとえば、能動学習が利用する機械学習モデルが、予測結果に自信がない事例を人間に提示し、ラベルを付与することで、機械学習モデルが苦手とする事例に対してうまく予測できるようになっていくことが期待されます。
以下の例では、事例をClass 1とClass 2に二値分類問題に対する分類器の予測結果と確率の分布を表しています。 左上の点 (事例) ほど分類器は自信を持ってClass 1と予測しており、右下の点ほど分類器は自信を持ってClass 2と予測しています。
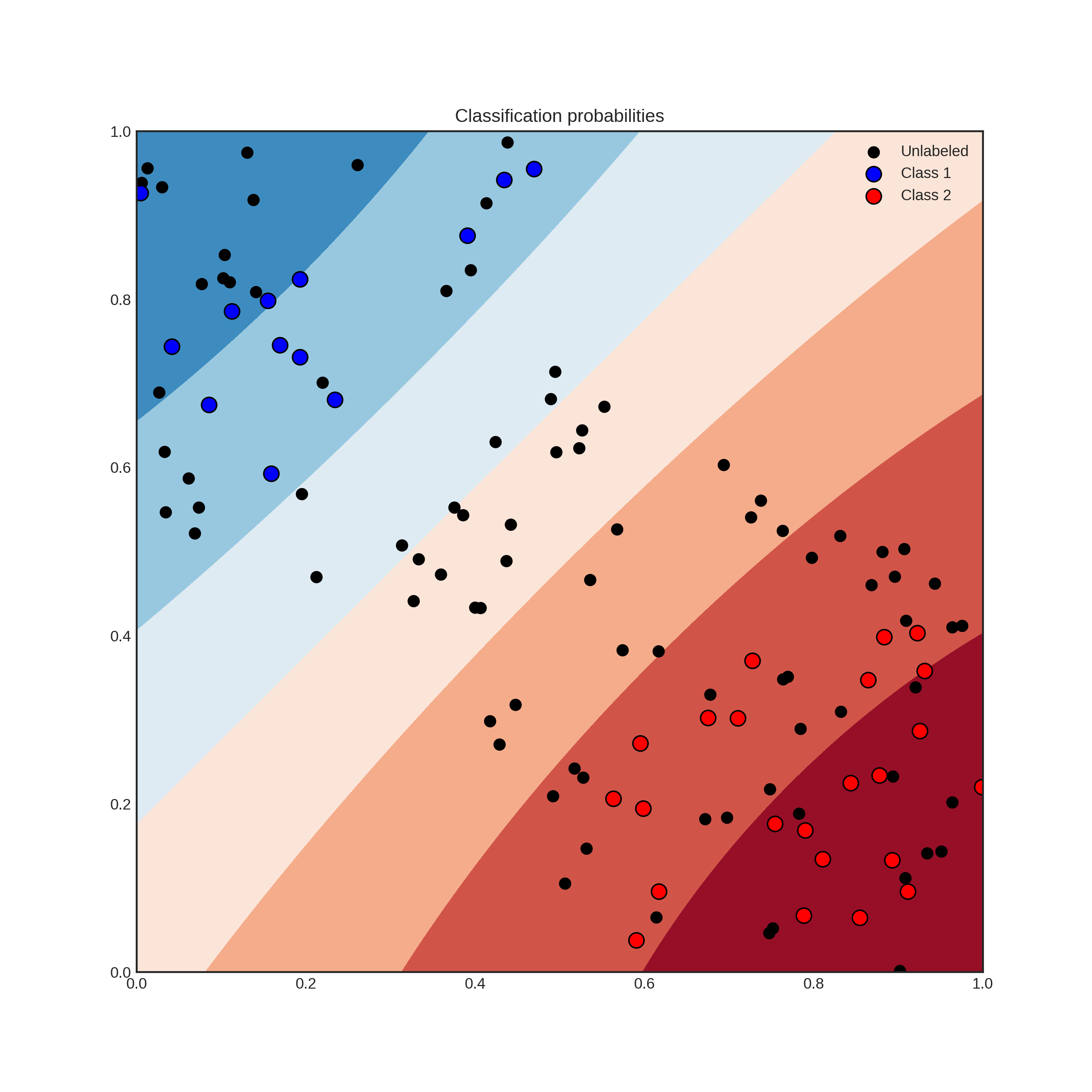 分類器の予測結果と予測確率。modALのドキュメントより引用。
分類器の予測結果と予測確率。modALのドキュメントより引用。
学習データを効率的に増やすには、未知の事例 (黒い点) の中でも、モデルの予測確率がどちらのクラスに対しても0.5付近の事例を集中的にラベル付けするのが良さそうです。 このようなモデルが自信のない事例を選択して、人にラベルを問い合わせるサイクルを能動学習OSSを使って実施できれば、楽して学習データを作成できそうです。
以下で能動学習のOSSを3つ調査し、概要をまとめました。
modAL
- pythonで実装されている
- scikit-learnのAPIに準拠していれば任意の分類器を利用可能
- ドキュメントにはKerasやPyTorchといったニューラルネットワークライブラリでの利用方法も記載
- ユニットテストやCIを利用するなどプログラムの品質にも気をつけている
- PyPIからインストール可能
ALiPy
- pythonで実装されている
- scikit-learnのAPIに準拠していれば任意の分類器を利用可能
- 20以上の最新の能動学習アルゴリズムを実装している
- PyPIからインストール可能
go-active-learning
- goで実装されている
- slackとの連携が可能
- URLを対象とした二値分類 (アルゴリズムはMIRA) に特化して実装されている
- URLからのHTML取得、HTMLからの本文抽出、テキストの前処理といった作業が不要
- 学習したモデルの分析が可能
余談になりますが機械学習に関するニュースを自動でまとめるウェブサービス (ML-News) でこのgo-active-learningがどのように使われているかを解説されている記事があり、能動学習に関する知見が参考になります1 2 3。
おわり
本記事では能動学習を利用するためのOSSについてまとめました。 ドキュメントが整備されており、比較的柔軟に利用しやすそうなのがmodAL、 最先端の能動学習を利用したいならAliPy、 利用方法が (主に日本語を対象とした) URLの二値分類であり、機械学習アルゴリズムや前処理などのカスタマイズが不要なのでしたらgo-active-learningといった印象を受けました。