argparseはPythonプログラムを実行する際の引数を解析し、それらの引数をPythonプログラム内部で利用できるようにするためのライブラリです。 コマンドラインから引数を受け付けるように実装することで、汎用性が高いプログラムを提供できるようになります。 本記事ではargparseの使い方の中でもよく使う基本的な利用方法をサンプルコード付きでまとめました。

本記事では文書分類に特化した自然言語処理ライブラリの開発について紹介します。 文書分類器一つを作るにも、前処理、開発、評価といった一連のプログラム開発に加えて、ニューラルネットワークに基づくモデルとそれ以外の機械学習アルゴリズムのどちらが良いのかといった比較を検討する必要もあったりと、かかる手間は少なくありません。 そこで、これらのプログラム開発をできるだけ簡易化するために開発した自然言語処理ライブラリを紹介します。 本記事を読むことで簡単に文書分類器を構築するためのライブラリの利用方法を理解できます。

本記事ではPythonでYouTube Data API v3を介して動画を検索する方法について紹介します。 ここ最近のYouTubeの盛り上がりによって多種多様で高品質な動画を無料で楽しむことができるようになってきました。 これらの動画情報をプログラミングで自動的に収集し、閲覧したり分析できるようになると便利ですよね。 そこで実際に動画情報を検索するPythonコードとともに利用例を説明します。 本記事を読むことで、YouTube動画の検索方法、検索対象のフィルタリングに加えて、検索では省略されてしまう概要欄全文の取得方法がわかります。
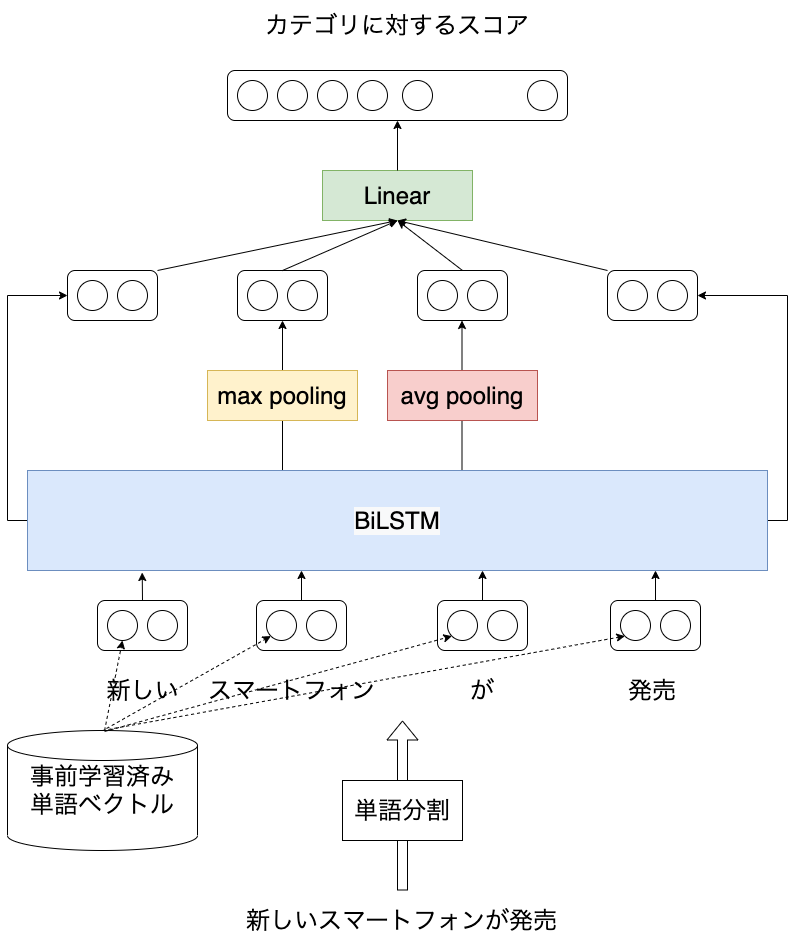
本記事では日本語を対象としたLSTMに基づく文書分類モデルをPyTorchコード付きで紹介します。 以前、LSTMを用いた言語モデルについて紹介しました ( [自然言語処理] LSTMに基づく言語モデルの学習 (PyTorchコード付き) ) が、ニューラルネットワークを用いた自然言語処理の応用例として文書分類のほうがイメージしやすそうなので、こちらについても紹介したいと思います。 実験にはライブドアコーパスから作成した、記事の見出しに対して9つのカテゴリのうち、どれか1つが付与されたデータを使います。 本記事を読むことで日本語を対象に、ニューラルネットワークを活用した自然言語処理の概要を知ることができます。 また、PyTorchで事前学習済みの単語分散表現を扱う方法も紹介しています。
本記事ではPyTorchを使ったニューラルネットワークの学習において、不要な計算グラフを削除することでできるだけメモリを節約するための方法を紹介します。 本記事を読むことで、少しでもGPUメモリの不足によるout of memoryエラーを減らしたり、よりバッチサイズを大きくしたりして学習を実施できるようになります。
Twitterの検索APIを利用することで、Twitterに投稿されるツイートを検索し、ツイート本文、いいね数などに加えて、ツイートに添付される画像やURLなどを取得できます。 Twitterの検索APIを利用するにはAPIや得られるデータの仕様を把握しておく必要があります。 本記事では、検索APIの主な仕様およびツイートに添付されている画像データやURLなどへのアクセス方法を紹介します。