
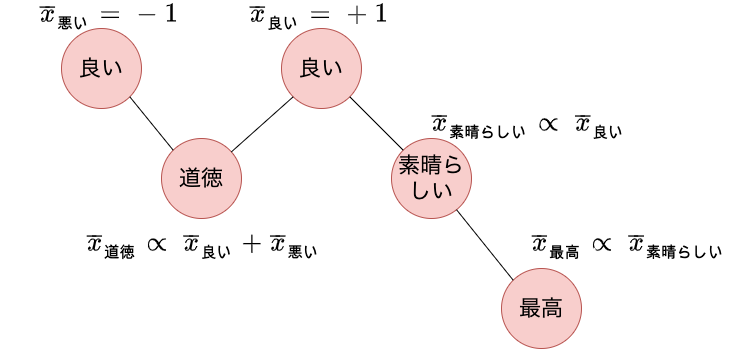
本記事では Takamuraら が提案した、spinモデルを用いてWordNetから単語の極性を学習する方法 (Extracting Semantic Orientations of Words using Spin Model, ACL’05) を紹介します。 自然言語処理ではテキストが良いことを言っているのか、悪いことを言っているのかを自動で推定する感情分析と呼ばれる研究があります。 感情分析をおこなうために、ある単語が良いことなのか、悪いことなのかを表す極性を含む知識源を活用するアプローチがあります。 近年ではラベル付きテキストコーパスを用意して、BERTを始めとするニューラルネットワークで分類モデルを学習するといった流れが主流ではありますが、このようなアプローチでも言語知識が活用できる余地はあります 1。 Takamuraらの論文は15年以上も前のものですが、単語の極性を獲得する論文としてよく引用されています。 また最近ではニューラルネットワークを使わない自然言語処理に触れる機会が少なくなったため勉強のため記事にします。

本記事ではWNGT 2020のefficiencyシェアドタスクに提出されたEfficient and High-Quality Neural Machine Translation with OpenNMTを紹介します。 このタスクでは精度だけではなく、省メモリ、高速であることに焦点を当てています。 自然言語処理タスクの多くはニューラルネットワークに基づく巨大なモデルによって最高精度が塗り替えられていますが、実用上は精度以外にもメモリや速度の観点を検討しなければならない場面が多く、現実に即したタスクとなっています。 紹介する論文では機械翻訳で実験を行っていますが、その他のタスクに対しても適用できそうなテクニックが多く、勉強になりそうだったので紹介することにしました。 このタスクに参加した他のシステムも精度や速度などの指標においてパレート曲線状にあり、それぞれのシステムが重きをおいた指標が異なっています。 本記事で紹介する論文は速度、省メモリに焦点を当てています。

本記事ではOn the Stability of Fine-tuning BERT: Misconceptions, Explanations, and Strong Baselinesという論文を紹介します。 この論文ではBERTのfine-tuningが安定しにくいという問題に対して、単純で良い結果が得られる方法を提案しています。 またBERTのfine-tuningが安定しにくいという問題を細かく分析しており、参考になったのでそのあたりについてもまとめます。 本記事を読むことでBERTを自分の問題でfine-tuningするときの施策を立てやすくなるかと思います。
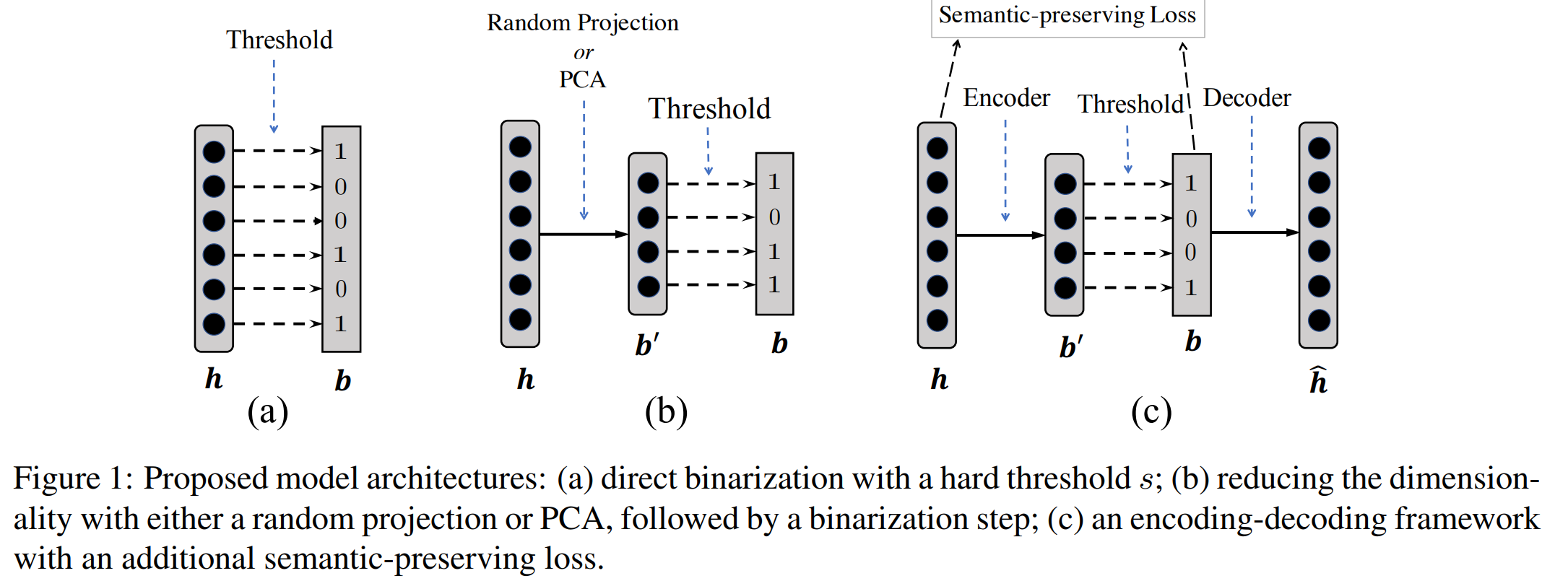
自然言語処理において、ニューラルネットワークは文や単語を実数値の密ベクトル表現に変換し、 得られた表現に基づいて目的のタスクを解くというアプローチが多い。 自然言語処理のさまざまなタスクで高い精度を上げている一方で、 テキスト検索などの高速な処理速度を要求されるような場面では密ベクトルを処理するのは 速度が遅いなどの実用的な課題がある。 自然言語処理に関する国際会議ACL 2019で発表された論文 ‘‘Learning Compressed Sentence Representations for On-Device Text Processing’’ (pdf) が、類似文検索タスクにおいて、検索精度をほぼ落とさずに、高速な検索がおこなえるように、文の表現を実数値ではなく、 二値ベクトルで表現する方法を提案した。 本記事ではこの論文でどういった技術が提案されているのかをまとめる。
(Structured Perceptron with Inexact Search, NAACL 2012) を読んだ。
構造化パーセプトロンは構造を持つ出力を予測するパーセプトロンであり、自然言語処理では品詞タグ付けなどに用いられる。出力を予測する際には効率的に出力を探索するために、ビームサーチが用いられることが多いが、一般的な構造化パーセプトロンに対してビームサーチを適用すると、パーセプトロンの収束性が保証されない。
構造化パーセプトロンを効率的に学習する手法として、early updateというヒューリスティクスな手法が提案されている。early updateは出力を予測する途中で正解でないとわかった段階で場合に重みを更新するヒューリスティクスな手法である。しかしながら、early updateはラベル列を最後まで見ずに重みを更新するのにも関わらず、violation fixingという枠組みで収束が保証される。
エッセイの一部をメモ。
主張をまとめると「自然言語の機械的な理解には、大規模なデータ、性能の良い機械学習も重要だけど、言語の構造をしっかり考えることも大事」。
Introduction Machine Comprehension of Text (MCT) (テキストの機械的理解) は人工知能のゴールである このゴールを達成したかどうかを確かめるために、研究者はよくチューリングテストを思い浮かべるが、Levesque (2013)が指摘するように、これは機械を知的に向かわせる、というよりは人間の知能を下げるほうに作業者を差し向けてしまう ※ チューリングテストとは、ある人間から見て、二人の対話のどちらが人間かどうか判別するテスト Levesqueはまた、チューリングテストよりも、世界知識を必要とするような選択肢が複数ある問題のほうが適しているとも主張している このエッセイでは、MCTは、“ネイティブスピーカーの大半が正しく答えられる質問に対して機械が答えた回答が、ネイティブスピーカーが納得できるものであり、かつ関連していない情報を含んでいなければ、その機械はテキストを理解しているもの"とする (つまり質問応答) このエッセイのゴールは、テキストの機械的理解という問題に何が必要なのかを観察することである How To Measure Progress 複数の選択肢がある質問応答のデータセットをクラウドソーシングを利用して作った 7歳の子供が読めるレベルのフィクションの短いストーリー Winograd Schema Test proposal (Levesque, 2013) は、質問と回答のペアは世界知識を要求するように注意深く設計されているので、生成には専門知識を要する質問を使うことを提案している “それは紙で出来ているので、ボールはテーブルから落ちた"の"それ"は何を指しているか? クラウドソーシングなのでスケーラビリティもある 進捗が早ければ、問題の難易度を上げることもできる 語彙数を現状の8000から増やす ノンフィクションなストーリーを混ぜる タスクの定義を変える 正解が1つ以上、あるいは正解が1つもない問題など 回答の根拠を出力するようにする 興味深いことは、ランダムな回答をするベースラインでは25%が正しい回答を得られる一方で、単純な単語ベースな手法が60%で、最近のモダンな含意認識システムを使っても60%くらいであることである Desiderata and some Recent Work machine comprehensionに必要なものは、興味深い未解決な問題と通じている
意味の表現は二つの意味でスケーラブルであるべきである、すなわち (1) 複数ソースのノイジーなデータから教師なし学習で学習できて、 (2) 任意のドメインの問題に適用できるべきである モデルが巨大で複雑になっても、推論はリアリタイムでおこなえるべきである 構築、デバッグの簡易化のためにシステムはモジュール化すべきである モジュラ性はシステムを効率的に反応できるようにするべきである エラーが起きた時に、何故それが起きたか理解可能にするために、各モジュールは解釈可能であるべきであり、同様にモジュールの構成も解釈可能であるべきである システムは単調的に修正可能であるべきである: 起きたエラーに対して、別のエラーを引き起こさずに、どのようにモデルを修正すればよいかが明白であるべきである システムは意味表現に対して論理的推論をおこなえるべきである システムの入力のテキストの意味表現とシステムの世界モデルを組み合わせることで論理的な結論をだせるべきである もろさを避けるため、また根拠を正しく結合するために、論理的思考は確率的であるべきなようである (Richardson and Domingos, 2006) システムは質問可能であるべきである 任意の仮説に関して、真であるかどうか (の確率) を断言することができること 私達はなぜその断言ができるか理解することができるべきである 最近の研究では 論理形式を文に対してタグ付けするなど、意味のモデル化はアノテーションコストがとても高い 興味深い代替手段としては、質問-回答のペアから論理形式を帰納するアノテーションがより低いものがある (Liang et al.
