【自然言語処理】spinモデルによる極性辞書の学習【論文紹介】
本記事では Takamuraら が提案した、spinモデルを用いてWordNetから単語の極性を学習する方法 (Extracting Semantic Orientations of Words using Spin Model, ACL’05) を紹介します。 自然言語処理ではテキストが良いことを言っているのか、悪いことを言っているのかを自動で推定する感情分析と呼ばれる研究があります。 感情分析をおこなうために、ある単語が良いことなのか、悪いことなのかを表す極性を含む知識源を活用するアプローチがあります。 近年ではラベル付きテキストコーパスを用意して、BERTを始めとするニューラルネットワークで分類モデルを学習するといった流れが主流ではありますが、このようなアプローチでも言語知識が活用できる余地はあります 1。 Takamuraらの論文は15年以上も前のものですが、単語の極性を獲得する論文としてよく引用されています。 また最近ではニューラルネットワークを使わない自然言語処理に触れる機会が少なくなったため勉強のため記事にします。
目次
WordNet
WordNetは意味辞書の一種です。同義語や、上位語・下位語といった単語の意味的な関係性が定義されています。さらに、単語の意味を説明する語釈文も定義されています。
語釈文とは単語の意味を説明する文のことで例えば「良い」「悪い」という単語に対して、WordNetでは以下のような語釈文を持ちます。本来はもっと多くの語釈文を持つのですがここではいくつか挙げます。
| 見出し語 | 語釈文 |
|---|---|
| 良い | 並み外れた優秀さの |
| 良い | 喜びを与えるさま |
| 良い | 優雅であるか高潔である |
| 良い | 道徳的な素晴らしさについて |
| 悪い | 低いか劣った品質の |
| 悪い | 不幸なさま |
| 悪い | 苦しみまたは逆境に終わるさま |
| 悪い | 道徳的に悪い、または間違っているさま |
このようにWordNetを参照することでその単語がどういった意味を持つのかを知ることができます。
単語の極性の学習
Takamuraらはspinモデルによって単語の極性を学習する方法を提案しました。極性は-1ならネガティブ、+1ならポジティブであるとします。この手法は最初に、単語間の関係を表す語彙ネットワークを構築します。次に、いくつかの単語に対して人手で極性を与えます。 「悪い」なら-1、「良い」なら+1といった具合で単語に対して極性を付与するとします。 その後、人手で極性が付与された単語を手がかりにに、語彙ネットワークを通して極性が付与されていない単語に対して極性を学習します。
語彙ネットワークの構築
まず、WordNetを用いて語彙ネットワークを構築します。 語彙ネットワークは、単語をノード、単語間の共起をリンクとするグラフです。 TakamuraらはWordNetの同義語、反義語の知識も利用していますがここでは語釈文を利用する場合についてのみ説明します。 以下の図はWordNetの語釈文から語彙ネットワークを構築する例です。 単語を単位とするため、形態素解析によって名詞、動詞、形容詞、形容動詞などの内容語を取得します。 その後、見出し語と語釈文の単語の間にリンクを作成します。
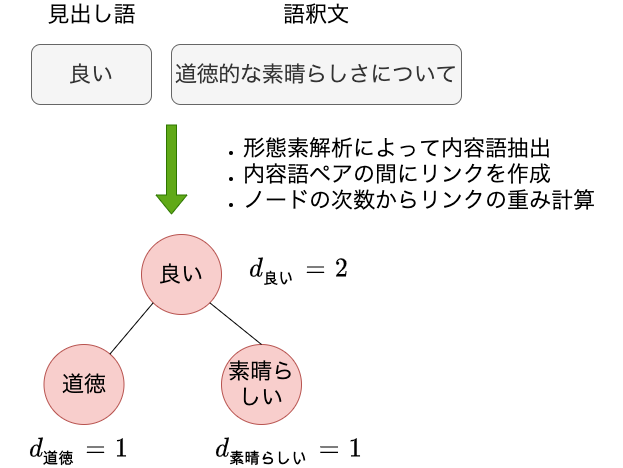 語彙ネットワークの構築
語彙ネットワークの構築
単語$i$と単語$j$の間のリンクの重み$w_{ij}$は以下のように計算します。 $$ \begin{eqnarray} w_{ij} = \frac{1}{\sqrt{d_i d_j}} \tag{1} \end{eqnarray} $$ $d_i$は単語$i$の次数、つまりリンクの数です。つまり$w_{i}{j}$は$i$と$j$のリンクが少ないほど大きな値になります。 どの単語とも共起する単語はリンクの重みが小さくなるように設計されています。 またこのリンクは見出し語と語釈文で共起する単語対に対して作成されます。 語釈文は見出し語を別の単語で説明するテキストなので、リンクがある単語対はだいたい同じ意味であることが期待されます。
spinモデルによる極性の学習
以下の図は「良い」という単語の極性を+1として与え、それとリンクを持つ単語に対して極性を伝搬しています。 「良い」とリンクを持つ「道徳」と「素晴らしい」という単語は「良い」の極性+1が伝搬されます。 また「道徳」は「悪い」という単語の極性も伝搬されます。 これにより、「素晴らしい」にはポジティブな極性が伝搬される一方で、「良い」「悪い」の両単語とリンクを持つ「道徳」はニュートラルな極性になります。 更に、ポジティブな極性を持つ「素晴らしい」とリンクを持つ「最高」にもポジティブな極性が伝搬されます。
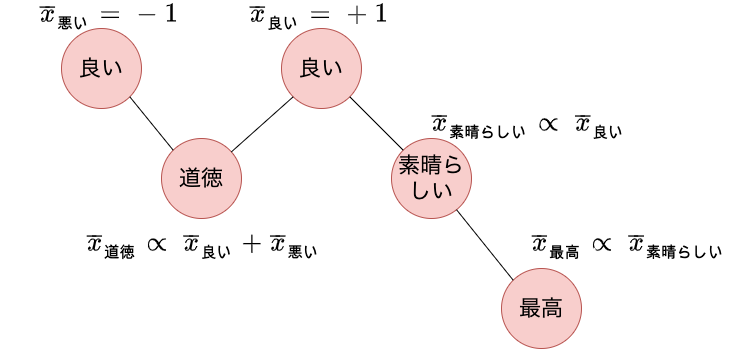 spinモデルによる極性の伝搬
spinモデルによる極性の伝搬
実際の極性の更新式は以下のようになり、値が収束するまで、すべてのノードの極性を更新し続けます。
$$ \begin{eqnarray} \bar{x}_i^{new} &=& \frac{ \sum_{x_i} x_i \exp(\beta x_i \sum_j w_{ij} \bar{x}_j) }{\sum_{x_i} \exp(\beta x_i \sum_j w_{ij} \bar{x}_j)} \tag{2} \end{eqnarray} $$
リンクの重み $w_{ij}$ と単語$j$の極性の平均$\bar{x}_j$の積の総和に基づいて、単語$i$の極性の平均$\bar{x}_i$を求めます。ただし$x_i \in \{-1, +1\}$です。 $\beta$はハイパーパラメータで、値が小さいほど、リンクがつながっている単語の極性を考慮しなくなります。 この式から、ポジティブな極性を持つ単語とリンクを持つ単語は、ポジティブな極性になることがわかります。
ただし、シードとして極性$a_i$を付与した単語に関しては以下の更新式を用います。 $\alpha$はハイパーパラメータで、値が大きいほどシードの極性から変動しないようにします。
$$ \begin{eqnarray} \bar{x}_i^{new} &=& \frac{ \sum_{x_i} x_i \exp(\beta x_i \sum_j w_{ij} \bar{x}_j - \alpha (x_i - a_i)^2) }{\sum_{x_i} \exp(\beta x_i \sum_j w_{ij} \bar{x}_j - \alpha (x_i - a_i)^2 )} \tag{3} \end{eqnarray} $$
学習結果
本来であれば単語の極性が人手で付与されたデータで実験をして分類精度が出せればよいのですが、ここでは簡単のため学習結果として得られた単語の極性を眺めます。 人手で「良い」をポジティブな単語、「悪い」をネガティブな単語として与えました。 なんとなく、ネガティブな単語は0以下の値となり、ポジティブな単語は0以上となっているように見えます。
-1 悪い
-0.0574371 ゆがみ
-0.0403787 塗炭
-0.0403787 悲酸
-0.0403787 惨状
-0.0401226 やんちゃ
-0.0400964 すり減らす
-0.0400964 すり減る
-0.0400964 擦り切れる
-0.0400964 擦切れる
-0.0400964 磨耗
-0.0360446 惨め
-0.0358467 さわぐ
-0.0358038 有徳
-0.0351372 ゆゆしい
-0.0350513 いとわしい
-0.0350396 卑怯
-0.0331313 事犯
-0.0331313 兇行
-0.0331313 凶行
-0.0331313 犯行
...
0.025582 ワンダフル
0.0258429 革める
0.026739 追い抜く
0.0267727 馨しい
0.0268865 奮励
0.0282495 さい先
0.028561 淫風
0.0288179 アップデート
0.0288179 バージョンアップ
0.0290066 見据える
0.0293322 似合う
0.0301709 郁々
0.0301709 郁郁
0.0301709 香しい
0.0303047 剋
0.0312687 好都合
0.0315503 昌平
0.0316 経あがる
0.0316 経上がる
0.0316479 体貌
0.0319193 チューンナップ
0.0319193 整調
0.0334086 人聞き
0.0334086 外聞
0.0352537 助命
0.0353999 白魔
0.0355824 香ばしい
0.03579 ヘルシー
0.0360915 人目
0.040364 届く
0.0407061 寡欲
0.0497152 おいしい
0.0500972 かぐわしい
0.0500972 匂やか
0.0513105 りっぱ
0.0522937 前途
1 良い
おわりに
本記事ではspinモデルによる単語の極性を学習する手法を紹介しました。 この手法はいくつかの単語に極性を人手で付与し、それを手がかりに他の極性がついていない単語の極性を学習します。 実際にC++で実装をして日本語WordNetで学習するところまで試しました。
最後に本記事のために開発した実装を以下に記載します。