
本記事ではscikit-learnを用いて自然言語処理モデルを構築する際に、tfidfに加えてそれ以外の特徴量を利用する方法をサンプルコード付きで紹介します。 scikit-learnで自然言語処理モデルを構築する際は、scikit-learnで用意されているクラスを用いて簡単にテキストをtfidfベクトルに変換することができます。 さらにscikit-learnでは種類の異なる特徴を容易に組み合わせるためのAPIも提供しています。 このAPIを用いることでtfidfに加えて、独自で実装した特徴量を考慮できます。 本記事を読むことで、独自の特徴を抽出するクラスを定義する方法に加えて、複数の特徴を組み合わせて利用するための方法を理解できます。

本記事では文書分類に特化した自然言語処理ライブラリの開発について紹介します。 文書分類器一つを作るにも、前処理、開発、評価といった一連のプログラム開発に加えて、ニューラルネットワークに基づくモデルとそれ以外の機械学習アルゴリズムのどちらが良いのかといった比較を検討する必要もあったりと、かかる手間は少なくありません。 そこで、これらのプログラム開発をできるだけ簡易化するために開発した自然言語処理ライブラリを紹介します。 本記事を読むことで簡単に文書分類器を構築するためのライブラリの利用方法を理解できます。

本記事ではOn the Stability of Fine-tuning BERT: Misconceptions, Explanations, and Strong Baselinesという論文を紹介します。 この論文ではBERTのfine-tuningが安定しにくいという問題に対して、単純で良い結果が得られる方法を提案しています。 またBERTのfine-tuningが安定しにくいという問題を細かく分析しており、参考になったのでそのあたりについてもまとめます。 本記事を読むことでBERTを自分の問題でfine-tuningするときの施策を立てやすくなるかと思います。
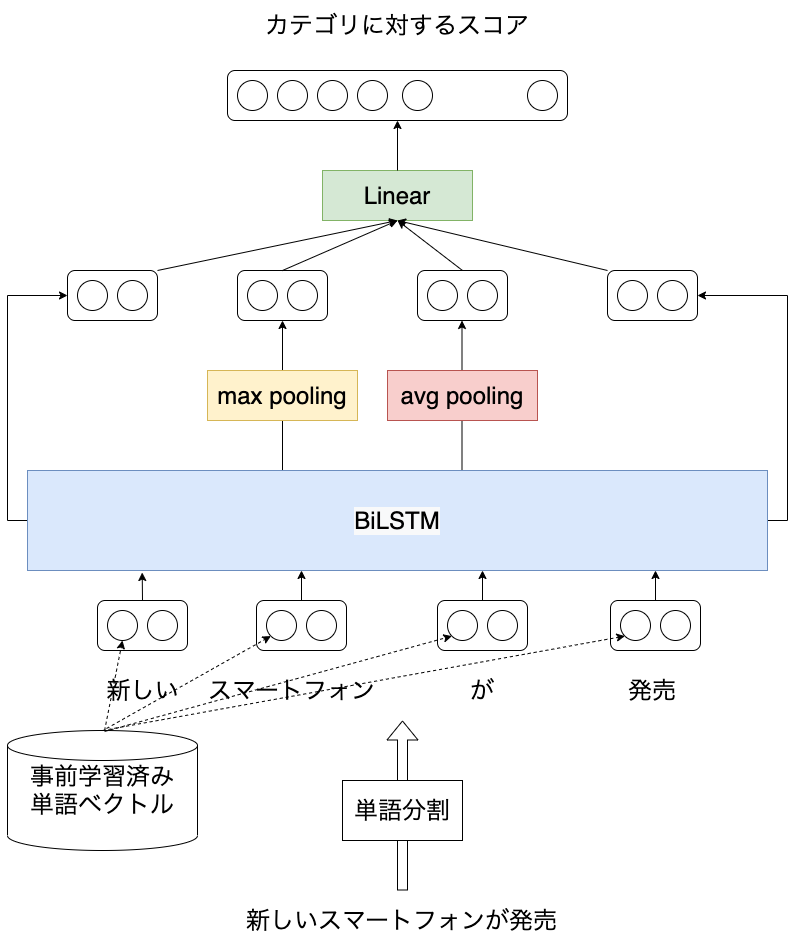
本記事では日本語を対象としたLSTMに基づく文書分類モデルをPyTorchコード付きで紹介します。 以前、LSTMを用いた言語モデルについて紹介しました ( [自然言語処理] LSTMに基づく言語モデルの学習 (PyTorchコード付き) ) が、ニューラルネットワークを用いた自然言語処理の応用例として文書分類のほうがイメージしやすそうなので、こちらについても紹介したいと思います。 実験にはライブドアコーパスから作成した、記事の見出しに対して9つのカテゴリのうち、どれか1つが付与されたデータを使います。 本記事を読むことで日本語を対象に、ニューラルネットワークを活用した自然言語処理の概要を知ることができます。 また、PyTorchで事前学習済みの単語分散表現を扱う方法も紹介しています。

ニューラル言語モデルはこれまでのn-gram言語モデルと比較して流暢なテキストを生成することができます。 ニューラル言語モデルの学習にはTeacher-forcingという方法がよく用いられます。 この手法はニューラル言語モデルの学習がしやすい一方で、テキスト生成時の挙動と乖離があります。 本記事では、Teacher-forcingを説明するとともに、この手法の課題を改善するための手法であるScheduled samplingを紹介します。

Kaggleの文書分類タスクにおける参加者のtipsがText Classification: All Tips and Tricks from 5 Kaggle Competitionsにまとまっていました。英語が前提になっているものの、参考になったので目を通し、概要をまとめました。 また日本語を対象とした場合に参考になりそうな記事も挙げておきます。
