
pybind11を使うことでC++で書いたライブラリをPythonから利用できるようになります。 例えばDeep LearningフレームワークのPyTorchもコア部分をC++で実装し、pybind11を使ってPythonから利用できるようになっています。 pybind11の公式リファレンスを読むことで基本的なことはわかったのですが、Pythonモジュールをサブモジュールごとにファイルに分割する方法がわからなかったので本記事を作成しました。 特にプログラムが複雑になってきたときにファイルを分割してサブモジュールを作成したいことが出てくると思います。 ベストプラクティスなのかわかりませんが、本記事が同じ疑問を持っている方の解決策になれば幸いです。
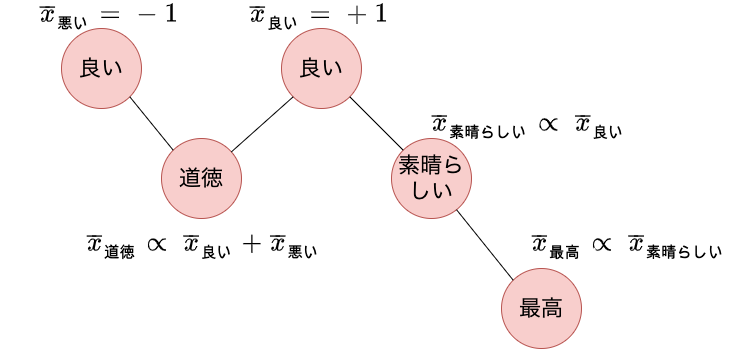
本記事では Takamuraら が提案した、spinモデルを用いてWordNetから単語の極性を学習する方法 (Extracting Semantic Orientations of Words using Spin Model, ACL’05) を紹介します。 自然言語処理ではテキストが良いことを言っているのか、悪いことを言っているのかを自動で推定する感情分析と呼ばれる研究があります。 感情分析をおこなうために、ある単語が良いことなのか、悪いことなのかを表す極性を含む知識源を活用するアプローチがあります。 近年ではラベル付きテキストコーパスを用意して、BERTを始めとするニューラルネットワークで分類モデルを学習するといった流れが主流ではありますが、このようなアプローチでも言語知識が活用できる余地はあります 1。 Takamuraらの論文は15年以上も前のものですが、単語の極性を獲得する論文としてよく引用されています。 また最近ではニューラルネットワークを使わない自然言語処理に触れる機会が少なくなったため勉強のため記事にします。

BERTの学習で用いるoptimizerでbiasやlayer normalizationのパラメータだけがweight decayの対象外となっていることについて疑問は持ったことはあるでしょうか。たとえばhuggingfaceのtransformersのissueでもそのような質問がありますが、「Googleの公開しているBERTがそうしているから再現性のために合わせた」と回答されています。ではなぜGoogleのBERT実装はそのような設定にしたのでしょうか。これらのOSSを利用されている方にも天下り的に設定している方もいらっしゃると思います。本記事ではBERTなどの学習で用いられるoptimizerのweight decayで、biasやlayer normalizationのパラメータが対象外となっている理由について解説します。

本記事ではWNGT 2020のefficiencyシェアドタスクに提出されたEfficient and High-Quality Neural Machine Translation with OpenNMTを紹介します。 このタスクでは精度だけではなく、省メモリ、高速であることに焦点を当てています。 自然言語処理タスクの多くはニューラルネットワークに基づく巨大なモデルによって最高精度が塗り替えられていますが、実用上は精度以外にもメモリや速度の観点を検討しなければならない場面が多く、現実に即したタスクとなっています。 紹介する論文では機械翻訳で実験を行っていますが、その他のタスクに対しても適用できそうなテクニックが多く、勉強になりそうだったので紹介することにしました。 このタスクに参加した他のシステムも精度や速度などの指標においてパレート曲線状にあり、それぞれのシステムが重きをおいた指標が異なっています。 本記事で紹介する論文は速度、省メモリに焦点を当てています。
本記事では「Who You Are(フーユーアー)君の真の言葉と行動こそが困難を生き抜くチームをつくる」を紹介します。 何らかの社会で生活していく上で、そこの文化は私達の行動に影響を与えます。 そのような文化というものが、どのように構築されていくのかということに興味が出て本書を読みました。 本書を読むことで、いくつかの事例を交えてそこから得られる教訓を知ることができます。 これから社会の中で同僚と働く際に指針を建てなければならない人たちには役に立つ書籍だと思います。
scikit-learnのTfidfVectorizerではテキストを単語分割するためのtokenizerを与えることができます。 日本語テキストを対象とする場合、日本語の形態素解析器であるMeCabのPythonラッパーが提供するTaggerを利用したオブジェクトをtokenizerと指定することがあるのではないでしょうか。 tokenizerにTaggerオブジェクトを指定したTfidfVectorizerをpickleで保存するとエラーが出てしまい、ファイルに書き出すことができません。 本記事ではMeCabのTaggerオブジェクトを活用したtokenizerによってテキストを単語分割するTfidfVectorizerをpickle化するための方法を紹介します。 本記事を読むことで独自に定義したクラスをpickleするための方法について理解できます。
本記事ではscikit-learnを用いて自然言語処理モデルを構築する際に、tfidfに加えてそれ以外の特徴量を利用する方法をサンプルコード付きで紹介します。 scikit-learnで自然言語処理モデルを構築する際は、scikit-learnで用意されているクラスを用いて簡単にテキストをtfidfベクトルに変換することができます。 さらにscikit-learnでは種類の異なる特徴を容易に組み合わせるためのAPIも提供しています。 このAPIを用いることでtfidfに加えて、独自で実装した特徴量を考慮できます。 本記事を読むことで、独自の特徴を抽出するクラスを定義する方法に加えて、複数の特徴を組み合わせて利用するための方法を理解できます。
