【自然言語処理】文書分類に特化したPythonライブラリを作り始めました【プログラムほぼ不要で使えます】
本記事では文書分類に特化した自然言語処理ライブラリの開発について紹介します。 文書分類器一つを作るにも、前処理、開発、評価といった一連のプログラム開発に加えて、ニューラルネットワークに基づくモデルとそれ以外の機械学習アルゴリズムのどちらが良いのかといった比較を検討する必要もあったりと、かかる手間は少なくありません。 そこで、これらのプログラム開発をできるだけ簡易化するために開発した自然言語処理ライブラリを紹介します。 本記事を読むことで簡単に文書分類器を構築するためのライブラリの利用方法を理解できます。
目次
背景
文書分類とは、与えられた文書に対して、事前に定義したラベル集合から適切なラベルを割り当てるような自然言語処理タスクです。 文書に対して自動でラベルを予測できる文書分類器は、自然言語処理を活用したモデルの中でもよく実応用に利用されているものの一つではないかと思います。
現在の文書分類アルゴリズムは機械学習に基づくものが主流です。 従来からよく用いられているSupport Vector Machines (SVM) やRandom Forestなどに加えて、最近ではニューラルネットワークに基づく文書分類器も提案され、ベンチマークデータにおいて高精度な結果が得られることが報告されています。 また、このようなアルゴリズムの高度化・多様化を支えている背景として、scikit-learnやPyTorchといった機械学習のフレームワークの発展を挙げることができます。
このように機械学習フレームワークの発展、アルゴリズムの高精度化が進んできたために、高品質な文書分類モデルを構築するための土台は整備がなされています。 しかしながら、これらの土台は依然として自然言語処理および機械学習の知識を有したプログラマがいることを前提としており、非専門家からするとまだまだ障壁があると感じられます。
たとえば、少人数の会社や個人開発において文書分類モデルを構築する作業は、開発内容全体からするとわずかであるのにも関わらず、専門的な知識を要するため、高コストとなりがちです。
さらに、SVMなどのアルゴリズムよりも高精度であると報告されていることが多いニューラルネットワークも、実際に適用する対象の文書分類タスクでも常にそうであるという保証はありません。 ニューラルネットワークとそれ以外のアルゴリズムで実際にどちらが高精度なのかを比較するのも、それぞれのアルゴリズムに適したフレームワークを使ってモデルを学習するプログラムを開発する必要があるため、開発コストがかさみます。
また実応用の面では、場合によっては精度だけでなく予測にかかる処理速度とのトレードオフも考えなければいけないこともあります。 仮に高精度であっても処理速度がアプリケーションの要件を満たさなければ使いづらいですよね。
開発したライブラリの紹介
上記の背景を鑑みて、アルゴリズムに依存したフレームワークに特化したプログラムを書かずに文書分類モデルを構築でき、かつそれらを精度の面だけでなく予測にかかる処理速度も比較できるようになったら便利なのではないかと思い、日曜大工の一環としてライブラリの開発をはじめました。
https://github.com/tma15/bunruija
設定ファイルとデータを用意すればモデルを用意できる: 利用者は、前処理、モデルのハイパーパラメータを記述した設定ファイル (yaml形式) と、学習データ・開発データ・評価データを用意すれば良いように設計しました。 実際の前処理、学習、評価部分はすべてライブラリがおこなうため、利用者はこれらの処理に対するプログラム開発が不要です。
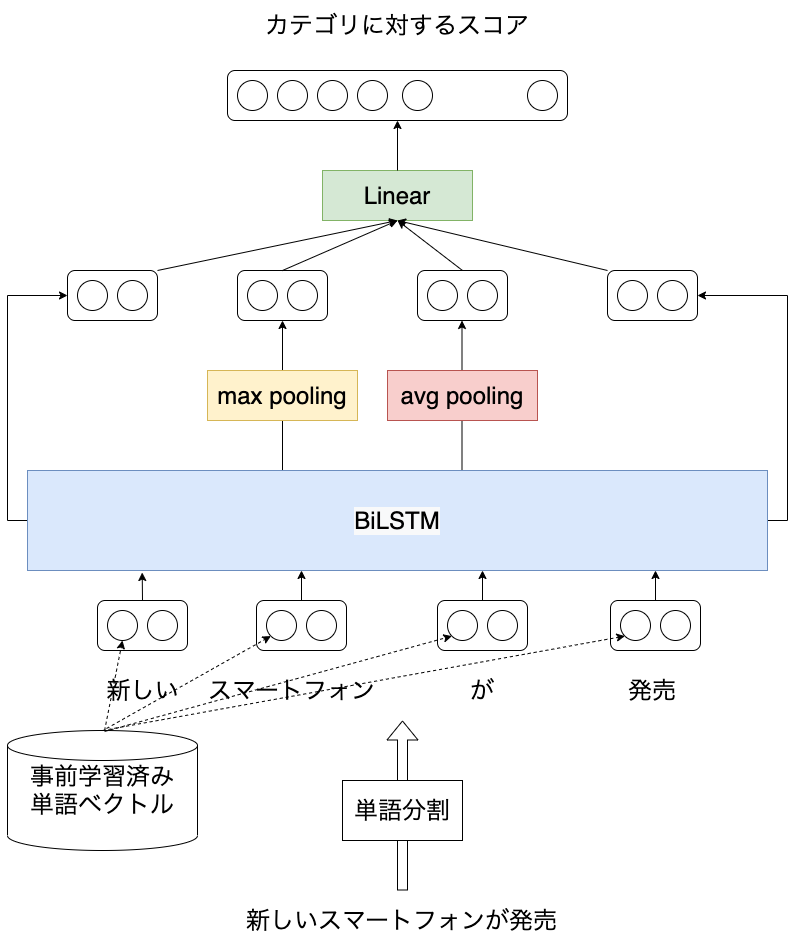
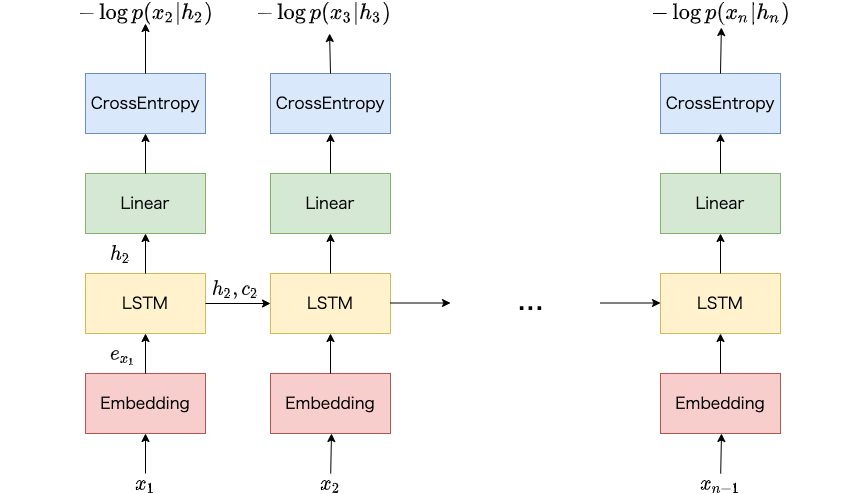
ニューラルネットワークとそれ以外のアルゴリズムの比較が簡単: このライブラリで利用可能なアルゴリズムはSVMやRandom Forestなどのアルゴリズムに加えて、ニューラルネットワークとなっています1。 これらのモデルの切り替えは設定ファイルでモデル名を指定するだけです。 そのため利用者は簡単にニューラルネットワークとそれ以外のアルゴリズムを比較することができます。
設定ファイルを残しておけばモデルの再現が容易: 前処理やモデルの学習部分で指定するハイパーパラメータは設定ファイルに記述されています。 文書分類の実験を再現したい場合、どういった設定をしたか記録を残しておかなければ難しくなってしまうのですが、ハイパーパラメータは設定ファイルに残されているため、他の人は再実験が容易になります。
主な使い方
bunruija-preprocess -y svm.yaml
bunruija-train -y svm.yaml
bunruija-evaluate -y svm.yaml
本ライブラリの利用手順は上記コマンドの3ステップからなります。 いずれのステップでも設定ファイルをコマンド引数として与えます。
たとえばsvm.yamlを以下のような内容となっています。
preprocess:
data:
train: train.csv
dev: dev.csv
test: test.csv
vectorizer:
type: tfidf
args:
max_features: 10000
min_df: 3
ngram_range:
- 1
- 3
tokenizer:
type: mecab
args:
lemmatize: true
exclude_pos:
- 助詞
- 助動詞
bin_dir: svm-model
classifier:
type: svm
args:
verbose: false
C: 10.
各ステップの入出力の概要図を以下に示します。
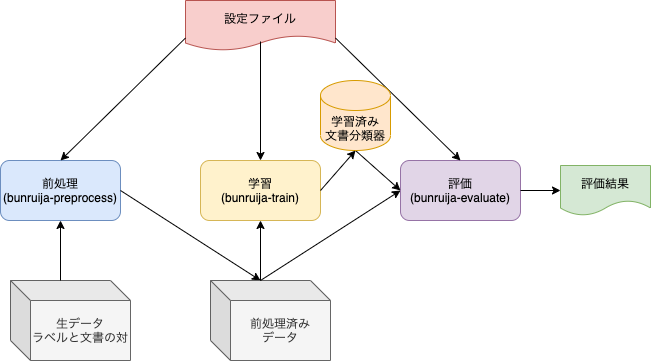 各処理の入出力を示す概要図
各処理の入出力を示す概要図
まず、前処理によって生データを特徴ベクトルに変換した前処理済みデータに変換します。 生データは文書とそれに対する正解ラベルが付与されたものになっています。 特徴ベクトルは形態素解析によって得られた単語列に基づいて構築するもので、SVMであればtfidf、ニューラルネットワークであれば単語をidに変換した系列となります。 学習データ、開発データ、評価データのそれぞれについて前処理を適用します。
その後、学習処理では前処理した結果を用いて文書分類器を学習し、学習済みの文書分類器をファイルに保存します。
最後に、前処理済み評価データを用いて学習済み文書分類器の精度及び予測速度を評価します。
おわり
本記事では文書分類に特化したPythonによる自然言語処理ライブラリを紹介しました。 日曜大工の一環として主に週末の空いた時間に作成しているため、開発速度は遅いのですが、こうしたライブラリ開発は勉強になるので少しずつ実装を進めるとともに、これを使った応用も検討してみたいと思います。
最後に、もし面白い取り組みだと思ったらstarをいただけるとモチベーション向上につながりますのでよろしくお願いします。
https://github.com/tma15/bunruija
-
ニューラルネットワークの学習ではGoogle ColabでのGPU学習にも対応しています。 ↩︎