

本記事では文書分類に特化した自然言語処理ライブラリの開発について紹介します。 文書分類器一つを作るにも、前処理、開発、評価といった一連のプログラム開発に加えて、ニューラルネットワークに基づくモデルとそれ以外の機械学習アルゴリズムのどちらが良いのかといった比較を検討する必要もあったりと、かかる手間は少なくありません。 そこで、これらのプログラム開発をできるだけ簡易化するために開発した自然言語処理ライブラリを紹介します。 本記事を読むことで簡単に文書分類器を構築するためのライブラリの利用方法を理解できます。
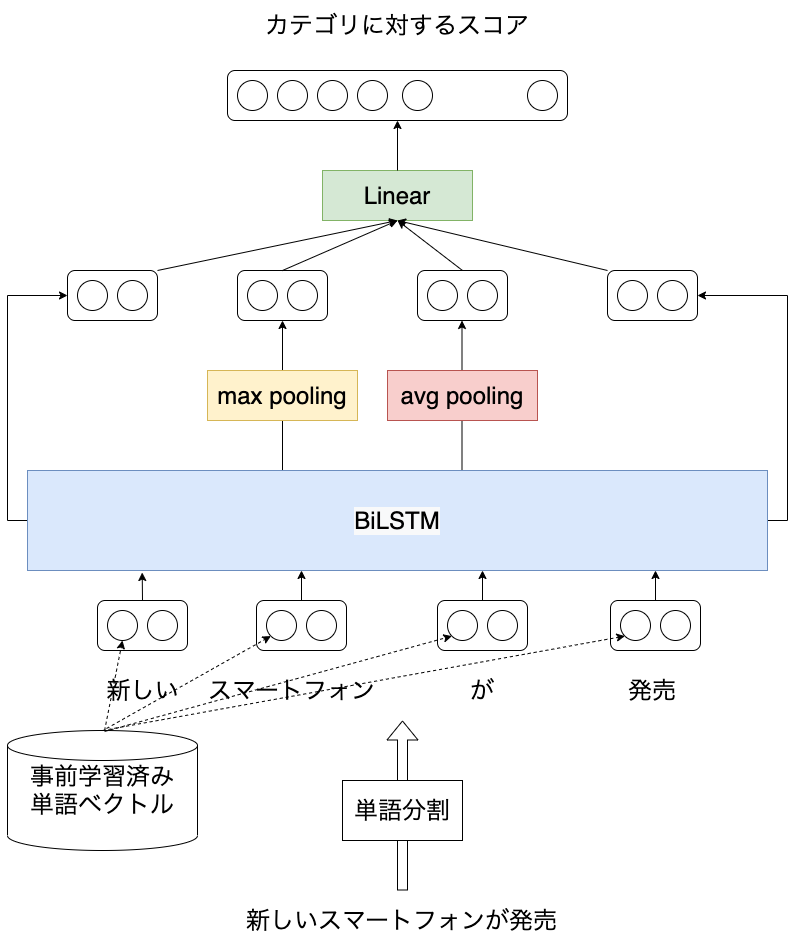
本記事では日本語を対象としたLSTMに基づく文書分類モデルをPyTorchコード付きで紹介します。 以前、LSTMを用いた言語モデルについて紹介しました ( [自然言語処理] LSTMに基づく言語モデルの学習 (PyTorchコード付き) ) が、ニューラルネットワークを用いた自然言語処理の応用例として文書分類のほうがイメージしやすそうなので、こちらについても紹介したいと思います。 実験にはライブドアコーパスから作成した、記事の見出しに対して9つのカテゴリのうち、どれか1つが付与されたデータを使います。 本記事を読むことで日本語を対象に、ニューラルネットワークを活用した自然言語処理の概要を知ることができます。 また、PyTorchで事前学習済みの単語分散表現を扱う方法も紹介しています。
本記事では画像認識系の国際会議 ECCV2020のチュートリアルでNVIDIAが発表した資料 PYTORCH PERFORMANCE TUNING GUIDE の内容をまとめるとともに、理解の助けになるような関連情報を参照します。 PyTorchは簡単にニューラルネットワークの実装のを容易さだけでなく、処理速度にも注意を払って開発が進められています。 プログラムにほんの少し修正を加えるだけで高速化できる可能性があります。 本記事を読み、実践することで、手元のPyTorchプログラム (特にGPUを使った学習処理) を高速化できる可能性があります。
本記事ではPyTorchを使ったニューラルネットワークの学習において、不要な計算グラフを削除することでできるだけメモリを節約するための方法を紹介します。 本記事を読むことで、少しでもGPUメモリの不足によるout of memoryエラーを減らしたり、よりバッチサイズを大きくしたりして学習を実施できるようになります。
PyTorchではDataLoaderを使うことで読み込んだデータから自動でミニバッチを作成することができます。 DataLoaderを使いこなすことで、ニューラルネットワークの学習部分を簡単に書くことができます。 本記事ではPyTorchのDataLoaderがミニバッチを作成する仕組みについて解説します。
