

本記事ではPythonのWebアプリケーションフレームワークの一つであるFlaskのblueprintの使い方について紹介します。 blueprintを使うことによって、アプリケーションをblueprint単位で分割できます。 特に規模が大きなアプリケーションほど、blueprintの利用によってアプリケーションを分割することでプログラムを管理しやすくなり、得られるメリットが大きいです。 本記事はFlask-Large-Aplication-Exampleを参考にして、特にblueprintに関する箇所を抽出し、簡素化して自分の理解をまとめたものです。 Flaskのblueprintを使って初めてアプリケーションを実装する人の参考になるような入門記事です。
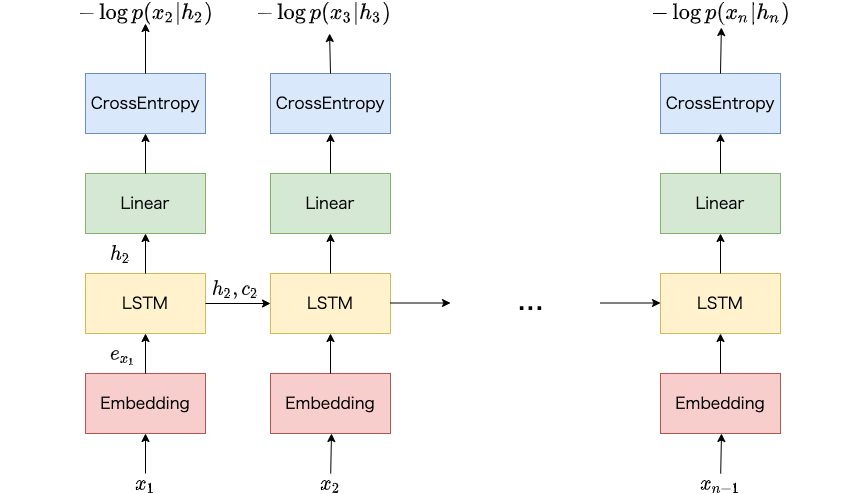
単語の系列 (たとえば文や文書) に対して確率を割り当てるようなモデルは言語モデルと呼ばれています。 古くはN-gram言語モデルが用いられました。 最近ではより広い文脈を考慮したり、単語スパースネスの問題に対処できるニューラルネットワークに基づく言語モデル (ニューラル言語モデル) が良く用いられます。 ニューラル言語モデルは文書分類、情報抽出、機械翻訳などの自然言語処理の様々なタスクで用いられます。 本記事ではコード付きでLSTMに基づく言語モデルおよびその学習方法を説明します。 本記事を読むことで、LSTMに基づく言語モデルの概要、学習の流れを理解できます。
本記事ではPythonとElasticsearchを使って、日本のレストランに関するデータを使って記事を検索エンジンにbulk APIを使って登録し、検索するまでを紹介する。
概要 mafというツールが便利そうだったのでメモ。 評価のために必要なめんどくさい処理が簡略化されそうな気がする。 実験結果の管理などがヘタなので、mafを使ってちょっとでもうまくなりたい。 まだ調べ始めたばかりなので、以降で出てくるコードよりももっとうまい書き方があると思う。
今回は色々とパラメータを変えて学習した分類器を評価する例で進める。
使ってみた まず、wafとmafとダウンロードする。
$cd /path/to/project/ $wget https://github.com/pfi/maf/raw/master/waf $wget https://github.com/pfi/maf/raw/master/maf.py $chmod +x waf 以下の様な wscript を作成。
#!/usr/bin/python import re import json import numpy as np import maf import maflib.util def configure(conf): pass @maflib.util.rule def jsonize(task): """ Calculate accuracy from a format as below: Recall[-1]: 0.932965 (21934/23510) Prec[-1]: 0.849562 (21934/25818) -- Recall[+1]: 0.478378 (3562/7446) Prec[+1]: 0.693266 (3562/5138) """ out = task.parameter with open(task.inputs[0].abspath(), 'r') as f: num = 0 num_trues = 0 for line in f: if line.
「高速文字列解析の世界」を一旦通読したので、実際に手を動かしてみた。 Induced Sortingは効率的に接尾辞配列を構築するアルゴリズム。 詳細はこの本を始め、下の参考にあるエントリなどが個人的に参考になった。
GitHubにコードを上げた (sais.py)。
参考 Suffix Array を作る - SA-IS の実装 https://github.com/beam2d/sara SA-IS: SuffixArray線形構築 実装時にはやはり元の論文を読まないとよくわからなかった。
Two Efficient Algorithms for Linear Time Suffix Array Construction
