

本記事ではPythonのWebアプリケーションフレームワークの一つであるFlaskのblueprintの使い方について紹介します。 blueprintを使うことによって、アプリケーションをblueprint単位で分割できます。 特に規模が大きなアプリケーションほど、blueprintの利用によってアプリケーションを分割することでプログラムを管理しやすくなり、得られるメリットが大きいです。 本記事はFlask-Large-Aplication-Exampleを参考にして、特にblueprintに関する箇所を抽出し、簡素化して自分の理解をまとめたものです。 Flaskのblueprintを使って初めてアプリケーションを実装する人の参考になるような入門記事です。
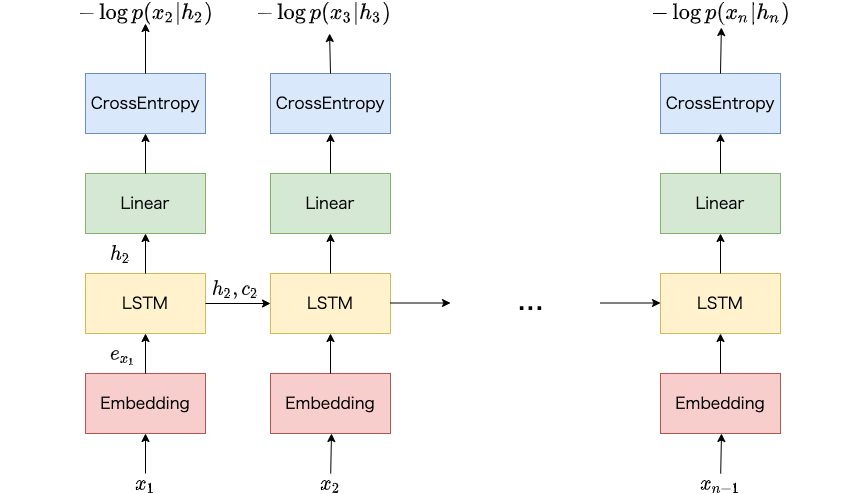
単語の系列 (たとえば文や文書) に対して確率を割り当てるようなモデルは言語モデルと呼ばれています。 古くはN-gram言語モデルが用いられました。 最近ではより広い文脈を考慮したり、単語スパースネスの問題に対処できるニューラルネットワークに基づく言語モデル (ニューラル言語モデル) が良く用いられます。 ニューラル言語モデルは文書分類、情報抽出、機械翻訳などの自然言語処理の様々なタスクで用いられます。 本記事ではコード付きでLSTMに基づく言語モデルおよびその学習方法を説明します。 本記事を読むことで、LSTMに基づく言語モデルの概要、学習の流れを理解できます。
本記事ではPythonとElasticsearchを使って、日本のレストランに関するデータを使って記事を検索エンジンにbulk APIを使って登録し、検索するまでを紹介する。
個人的にはプログラミングの勉強は写経が一番頭に入る気がする、ということで読んでいた。
気になったところ データに正規分布を仮定したときのナイーブベイズ分類器について。 平均を\(\mu\)、分散を\(\sigma^2\)としたときの正規分布は
\[ p(x;\mu, \sigma^2) = \frac{1}{\sqrt{2\pi \sigma^2}} \{\exp{-\frac{(x-\mu)^2}{2\sigma^2}}\} \]
これのlogをとると、
$$ \begin{eqnarray} \log p(x;\mu, \sigma^2) &=& \log \{\frac{1}{\sqrt{2\pi \sigma^2}} \{\exp{-\frac{(x-\mu)^2}{2\sigma^2}}\}\} \\\
&=& -\frac{1}{2}\log (2\pi \sigma^2) - \frac{(x-\mu)^2}{2\sigma^2} \end{eqnarray} $$
ナイーブベイズ分類器の対数尤度関数は、データがK次元ベクトルで表現されていて、それがN個あるとすると、 $$ \begin{eqnarray} \log L(X, Y; \mu, \sigma) &=& \log(\prod_{n=1}^N p(\mathbf{x}_n, y_n))\\\
&=& \log(\prod_{n=1}^N p(y_n)p(\mathbf{x}_n|y_n))\\\
&=& \sum_{n=1}^N \log p(y_n) + \sum_{n=1}^N \log p(\mathbf{x}_n|y_n)\\\
&=& \sum_{n=1}^N \log p(y_n) + \sum_{n=1}^N \sum_{k=1}^K\log p(x_{nk}|y_n)\\\
&=& \sum_{n=1}^N \log p(y_n) + \sum_{n=1}^N \sum_{k=1}^K \{-\frac{1}{2}\log (2\pi \sigma_{y_nk}^2) - \frac{(x_{nk}-\mu_{y_nk})^2}{2\sigma_{y_nk}^2}\} \end{eqnarray} $$
