

ニューラル言語モデルはこれまでのn-gram言語モデルと比較して流暢なテキストを生成することができます。 ニューラル言語モデルの学習にはTeacher-forcingという方法がよく用いられます。 この手法はニューラル言語モデルの学習がしやすい一方で、テキスト生成時の挙動と乖離があります。 本記事では、Teacher-forcingを説明するとともに、この手法の課題を改善するための手法であるScheduled samplingを紹介します。
Kaggleの文書分類タスクにおける参加者のtipsがText Classification: All Tips and Tricks from 5 Kaggle Competitionsにまとまっていました。英語が前提になっているものの、参考になったので目を通し、概要をまとめました。 また日本語を対象とした場合に参考になりそうな記事も挙げておきます。
stackingはアンサンブル学習と呼ばれる機械学習の一種で、他の機械学習に基づく複数の予測モデルの出力を入力の一部として扱い、予測モデルを構築します。 単純なアルゴリズムであるのにもかかわらず、何かしらの分類器単体よりも高い予測精度を得やすく、予測精度を競うようなコンペにおいて良く用いられています。 本記事ではscikit-learnのバージョン0.22で導入されたStackingClassifierの使い方について紹介するとともに、学習時の挙動を紹介します。 本記事を読むことでscikit-learnでのstackingの学習の流れを理解できます。
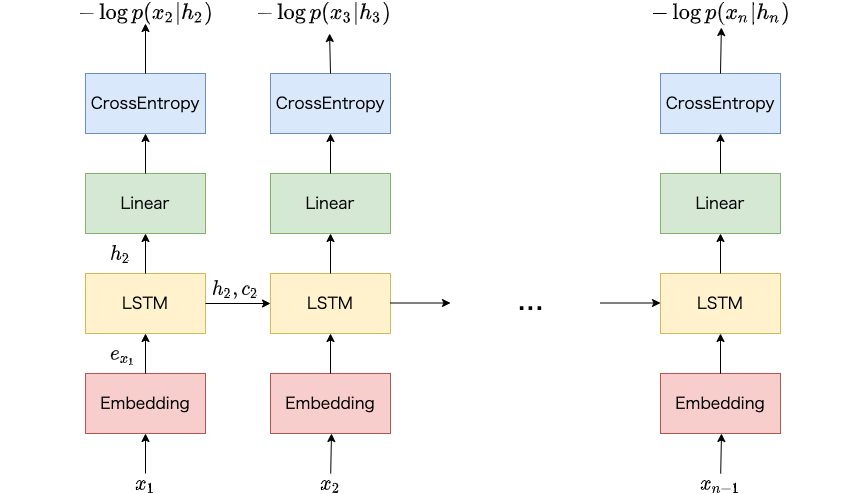
単語の系列 (たとえば文や文書) に対して確率を割り当てるようなモデルは言語モデルと呼ばれています。 古くはN-gram言語モデルが用いられました。 最近ではより広い文脈を考慮したり、単語スパースネスの問題に対処できるニューラルネットワークに基づく言語モデル (ニューラル言語モデル) が良く用いられます。 ニューラル言語モデルは文書分類、情報抽出、機械翻訳などの自然言語処理の様々なタスクで用いられます。 本記事ではコード付きでLSTMに基づく言語モデルおよびその学習方法を説明します。 本記事を読むことで、LSTMに基づく言語モデルの概要、学習の流れを理解できます。
ニューラルネットワークの学習には、複数の事例 (たとえば単語の系列) に対して並列に損失関数を計算し、得られた勾配に基づいてパラメータを更新するミニバッチ学習が用いられます。自然言語処理において、ミニバッチ学習時は単語の系列を同じ長さにそろえて処理します。これはニューラルネットワーク内での計算において、データが密行列として扱われることが多いためです。 この長さをそろえる処理はパディングといわれています。 当然ながら、ミニバッチ内で系列の長さが不ぞろいなほど、パディングによって追加される疑似的な単語が増えるため、本来不要な計算が増えます。また、ミニバッチを表す密行列が大きいほど、計算にかかる時間が大きくなります。 本記事ではPyTorchにおける実装において、系列の長さが近い事例でミニバッチを作成することで、不要なパディングをできるだけ減らし、ミニバッチを表す密行列の大きさを小さくする方法を紹介します。
ニューラルネットワークを用いた自然言語処理では、大量のラベルなしテキストを利用した事前学習によって、目的のタスクの予測モデルの精度を改善することが報告されています。 事前学習に用いるテキストの量が多いと、データを計算機上のメモリに一度に載りきらない場合があります。 この記事ではPyTorchでニューラルネットワークの学習を記述する際に、テキストをファイルに分割して、ファイル単位でテキストを読み込むことで、計算機上で利用するメモリの使用量を節約する方法を紹介します。
