
本記事ではPythonにおいて複数の入力を列挙する関数であるzip、zip_longestおよびそれらの違いを紹介します。
また、これらの関数は入力の長さが異なっていても動作するため、
同じ長さを保証するように入力の要素を列挙する方法も紹介します。
stackingはアンサンブル学習と呼ばれる機械学習の一種で、他の機械学習に基づく複数の予測モデルの出力を入力の一部として扱い、予測モデルを構築します。 単純なアルゴリズムであるのにもかかわらず、何かしらの分類器単体よりも高い予測精度を得やすく、予測精度を競うようなコンペにおいて良く用いられています。 本記事ではscikit-learnのバージョン0.22で導入されたStackingClassifierの使い方について紹介するとともに、学習時の挙動を紹介します。 本記事を読むことでscikit-learnでのstackingの学習の流れを理解できます。

本記事ではPythonのWebアプリケーションフレームワークの一つであるFlaskのblueprintの使い方について紹介します。 blueprintを使うことによって、アプリケーションをblueprint単位で分割できます。 特に規模が大きなアプリケーションほど、blueprintの利用によってアプリケーションを分割することでプログラムを管理しやすくなり、得られるメリットが大きいです。 本記事はFlask-Large-Aplication-Exampleを参考にして、特にblueprintに関する箇所を抽出し、簡素化して自分の理解をまとめたものです。 Flaskのblueprintを使って初めてアプリケーションを実装する人の参考になるような入門記事です。
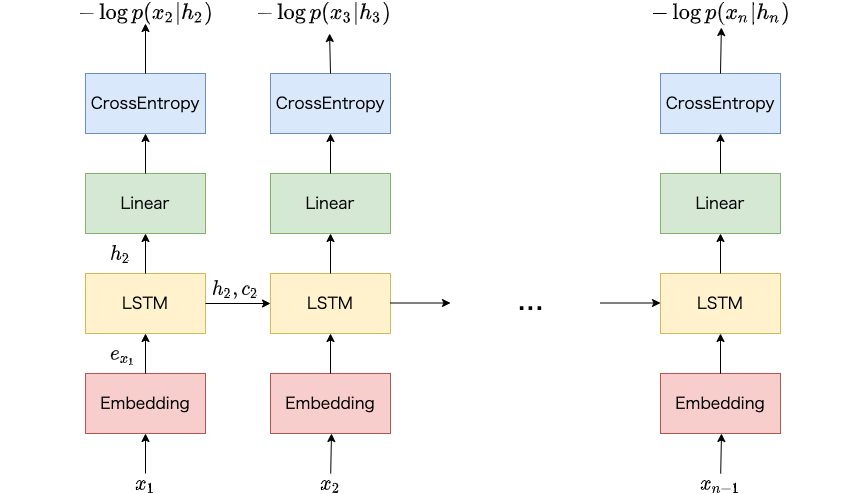
単語の系列 (たとえば文や文書) に対して確率を割り当てるようなモデルは言語モデルと呼ばれています。 古くはN-gram言語モデルが用いられました。 最近ではより広い文脈を考慮したり、単語スパースネスの問題に対処できるニューラルネットワークに基づく言語モデル (ニューラル言語モデル) が良く用いられます。 ニューラル言語モデルは文書分類、情報抽出、機械翻訳などの自然言語処理の様々なタスクで用いられます。 本記事ではコード付きでLSTMに基づく言語モデルおよびその学習方法を説明します。 本記事を読むことで、LSTMに基づく言語モデルの概要、学習の流れを理解できます。

Google Colaboratory (略称: Colab) はGoogleが提供する無料の計算環境です。 ウェブブラウザ上でコードを記述して実行できるインタラクティブな操作ができます。 さらにGPUやTPUを無料で利用できる素晴らしい計算環境です。 本記事ではColabを利用するための計算環境の構築手順を紹介します。 またハードウェアやエディタといった計算環境のカスタマイズの方法や、自分で作成したプログラム資産をColab上でも活用する方法も紹介します。
ニューラルネットワークの学習には、複数の事例 (たとえば単語の系列) に対して並列に損失関数を計算し、得られた勾配に基づいてパラメータを更新するミニバッチ学習が用いられます。自然言語処理において、ミニバッチ学習時は単語の系列を同じ長さにそろえて処理します。これはニューラルネットワーク内での計算において、データが密行列として扱われることが多いためです。 この長さをそろえる処理はパディングといわれています。 当然ながら、ミニバッチ内で系列の長さが不ぞろいなほど、パディングによって追加される疑似的な単語が増えるため、本来不要な計算が増えます。また、ミニバッチを表す密行列が大きいほど、計算にかかる時間が大きくなります。 本記事ではPyTorchにおける実装において、系列の長さが近い事例でミニバッチを作成することで、不要なパディングをできるだけ減らし、ミニバッチを表す密行列の大きさを小さくする方法を紹介します。
