
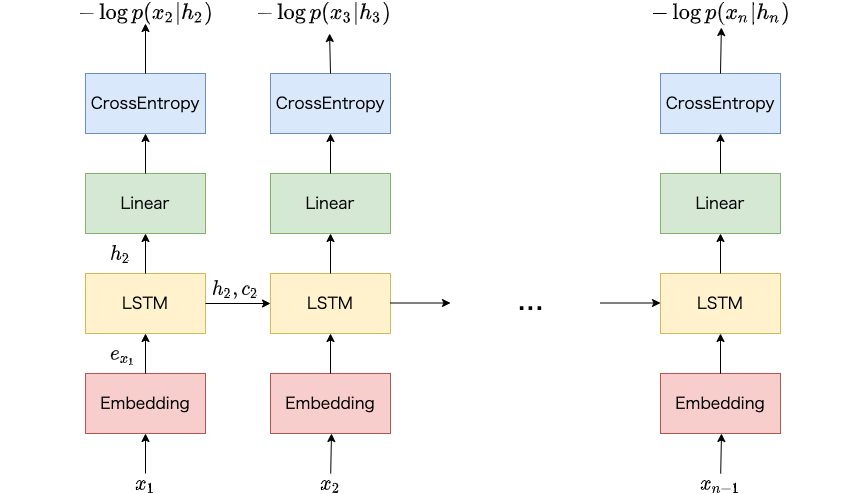
単語の系列 (たとえば文や文書) に対して確率を割り当てるようなモデルは言語モデルと呼ばれています。 古くはN-gram言語モデルが用いられました。 最近ではより広い文脈を考慮したり、単語スパースネスの問題に対処できるニューラルネットワークに基づく言語モデル (ニューラル言語モデル) が良く用いられます。 ニューラル言語モデルは文書分類、情報抽出、機械翻訳などの自然言語処理の様々なタスクで用いられます。 本記事ではコード付きでLSTMに基づく言語モデルおよびその学習方法を説明します。 本記事を読むことで、LSTMに基づく言語モデルの概要、学習の流れを理解できます。
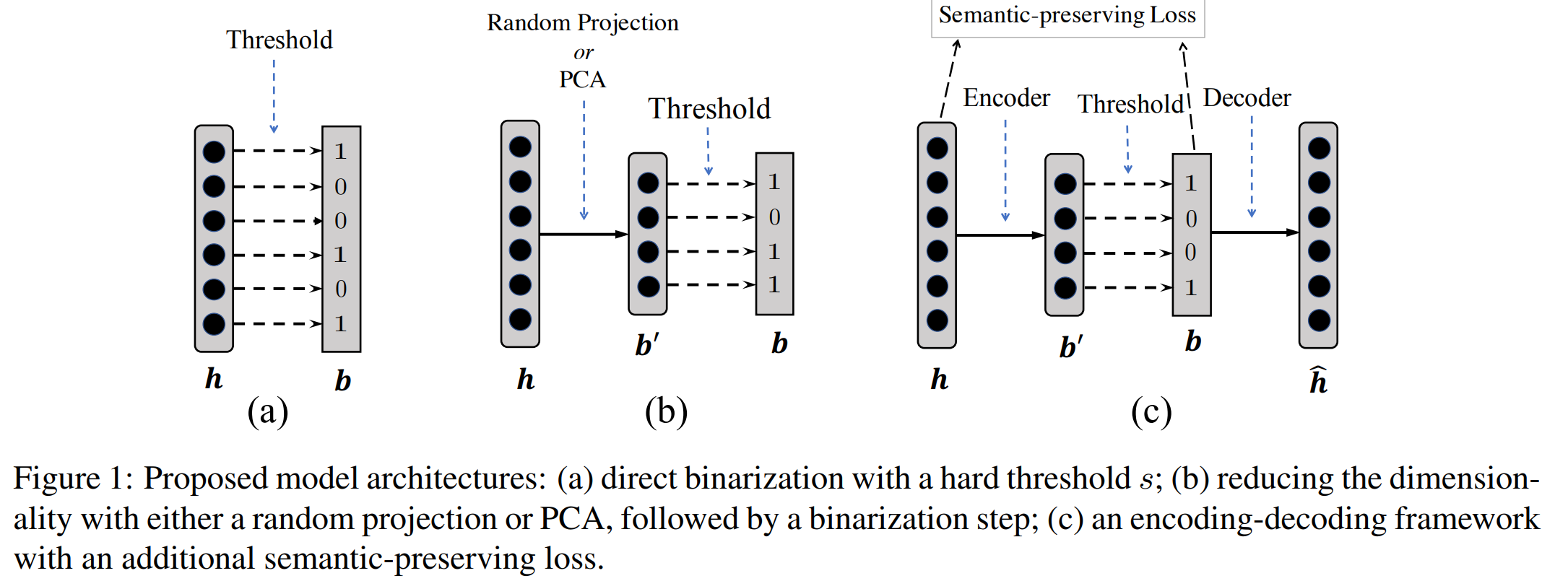
自然言語処理において、ニューラルネットワークは文や単語を実数値の密ベクトル表現に変換し、 得られた表現に基づいて目的のタスクを解くというアプローチが多い。 自然言語処理のさまざまなタスクで高い精度を上げている一方で、 テキスト検索などの高速な処理速度を要求されるような場面では密ベクトルを処理するのは 速度が遅いなどの実用的な課題がある。 自然言語処理に関する国際会議ACL 2019で発表された論文 ‘‘Learning Compressed Sentence Representations for On-Device Text Processing’’ (pdf) が、類似文検索タスクにおいて、検索精度をほぼ落とさずに、高速な検索がおこなえるように、文の表現を実数値ではなく、 二値ベクトルで表現する方法を提案した。 本記事ではこの論文でどういった技術が提案されているのかをまとめる。
