
ニューラルネットワークを用いた自然言語処理では、大量のラベルなしテキストを利用した事前学習によって、目的のタスクの予測モデルの精度を改善することが報告されています。 事前学習に用いるテキストの量が多いと、データを計算機上のメモリに一度に載りきらない場合があります。 この記事ではPyTorchでニューラルネットワークの学習を記述する際に、テキストをファイルに分割して、ファイル単位でテキストを読み込むことで、計算機上で利用するメモリの使用量を節約する方法を紹介します。
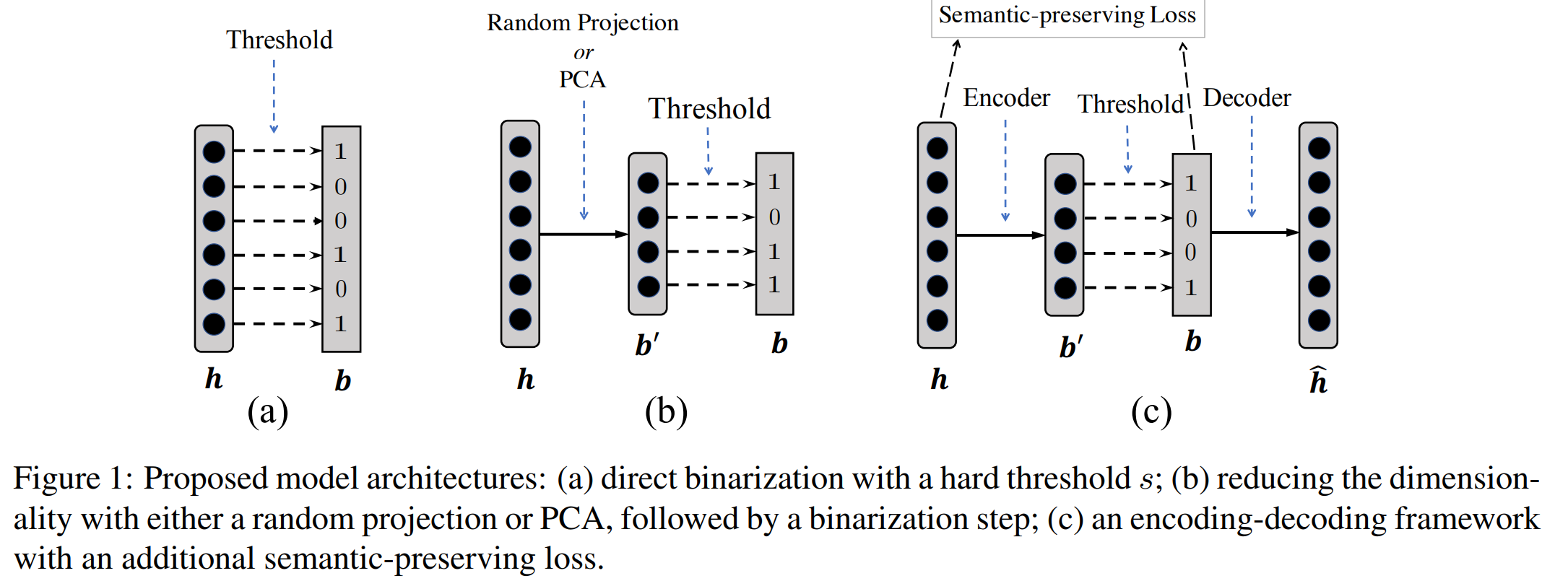
自然言語処理において、ニューラルネットワークは文や単語を実数値の密ベクトル表現に変換し、 得られた表現に基づいて目的のタスクを解くというアプローチが多い。 自然言語処理のさまざまなタスクで高い精度を上げている一方で、 テキスト検索などの高速な処理速度を要求されるような場面では密ベクトルを処理するのは 速度が遅いなどの実用的な課題がある。 自然言語処理に関する国際会議ACL 2019で発表された論文 ‘‘Learning Compressed Sentence Representations for On-Device Text Processing’’ (pdf) が、類似文検索タスクにおいて、検索精度をほぼ落とさずに、高速な検索がおこなえるように、文の表現を実数値ではなく、 二値ベクトルで表現する方法を提案した。 本記事ではこの論文でどういった技術が提案されているのかをまとめる。
このエントリではSWIGを使ったPythonラッパーの生成をautomakeでおこなう方法を紹介する。
例えば自然言語処理でよく使われているMeCabやCRFsuiteなどのC++実装にはPythonラッパーが付属していることがある。C++実装を呼び出せるPythonラッパーがあれば、計算量が多くなりやすい機械学習部分だけC++で実装して、他の処理部分はPythonで手軽に書いて運用する、であるとかC++には不慣れであってもPythonなら使ったことがある、というユーザにも利用してもらう、といったことができるようになる。C++ではSWIGを用いて他の言語へのラッパーを生成することができ、MeCabやCRFsuiteなども、SWIGを使ってPythonラッパーを生成している。
またSWIGによるラッパーの生成の手続きは設定が面倒であったりするため、MeCabやCRFsuiteがおこなっているような、automakeで出来るだけ簡略化する作業も調べてまとめる。
