
ニューラルネットの出力ベクトルを二値化して検索を高速化させる方法
自然言語処理において、ニューラルネットワークは文や単語を実数値の密ベクトル表現に変換し、 得られた表現に基づいて目的のタスクを解くというアプローチが多い。 自然言語処理のさまざまなタスクで高い精度を上げている一方で、 テキスト検索などの高速な処理速度を要求されるような場面では密ベクトルを処理するのは 速度が遅いなどの実用的な課題がある。 自然言語処理に関する国際会議ACL 2019で発表された論文 ‘‘Learning Compressed Sentence Representations for On-Device Text Processing’’ (pdf) が、類似文検索タスクにおいて、検索精度をほぼ落とさずに、高速な検索がおこなえるように、文の表現を実数値ではなく、 二値ベクトルで表現する方法を提案した。 本記事ではこの論文でどういった技術が提案されているのかをまとめる。
目次
そもそも文が実数値密ベクトルだと何が問題なのか?
| ベクトル間の類似度計算 | 表現力 | メモリ消費量 | 類似度計算速度 | |
|---|---|---|---|---|
| 実数値ベクトル | コサイン類似度 | 高い | 多い | 遅い |
| 二値ベクトル | ハミング距離 | 低い | 少ない | 速い |
ニューラルネットワークによって文をベクトルへ変換すると、多くの場合、そのベクトルは実数値の密ベクトル である。 文を実数値の密ベクトルで表現すると、たとえば類似する文を検索するタスクにおいて、クエリとなる文や 検索対象とする文はニューラルネットワークによって$[0.3, 0.1, -1.0, -2.3, 3.1, 1.7, …]$のように表現され、クエリのベクトルと検索対象の文のベクトルの間の類似度 (コサイン類似度) を計算する。 このように文を表現して類似度を計算する場合、
- メモリ消費が少なくない、 2) クエリに対する類似度計算 (コサイン類似度) にかかる処理時間が少なくない といった問題がある。計算環境が貧弱なほど、これらの問題は重大となる。
文を二値ベクトル$[1, 0, 1, 0, 0, 1, …]$で表現した場合と対比して考えてみる。
ベクトルの要素が二値で表現できれば例えば値の型は unsigne char で表現できるが、
ベクトルの要素が実数値であれば値の型は float で表現する必要がある。
また二値ベクトルであれば類似度計算にはハミング距離を使って高速に計算できる。
実数値ベクトルであればコサイン類似度を使って計算する必要がある。
提案手法のどこがいいのか?
- テキストから密ベクトルへ変換するモデルは何でもいい
- 二値ベクトルの次元は自由に設定できる
1について。処理の流れとしては文→密ベクトル→二値ベクトルとなるのだが、この論文は密ベクトル→二値ベクトル のところをどうやるか、というところを対象としていて、文から密ベクトル変換する処理がなんであってもよい。 文→密ベクトル→二値ベクトルをend-to-endで学習するというアプローチも考えられるが、 先行研究でもこの論文の予備実験でも、精度の低下がみられるという報告がされている。
2について。提案手法は密ベクトルの次元によらず、二値ベクトルの次元を自由に設定できる。 メモリが限られた状況においては、二値ベクトルの次元をもとの密ベクトルの次元よりも小さくすることでメモリの消費を削減できる。
どれくらい高速化されるのか?精度は落ちないのか?
a) 文を密ベクトルで表現し、コサイン類似度を計算、 b) 文を二値ベクトルで表現し、ハミング距離を計算、という2パターンに対して、$10,000$の文のペアの類似度を計算し、それぞれ計算にかかった時間を計測して、パターンbの二値ベクトルで表現、ハミング距離を計算するほうが、 パターンaよりも12倍高速に処理できたとのこと。 ただしベクトルの次元はaとbで同じ。実験で用いた多くのタスクで二値ベクトルによる類似度計算の精度は、密ベクトルによる類似度計算の精度の2%程度の低下にとどまっている。
また二値ベクトルの次元を小さくした場合においても (一部の手法では) あまり精度の低下は見られない。
どうやって密ベクトルを二値ベクトルにするのか?
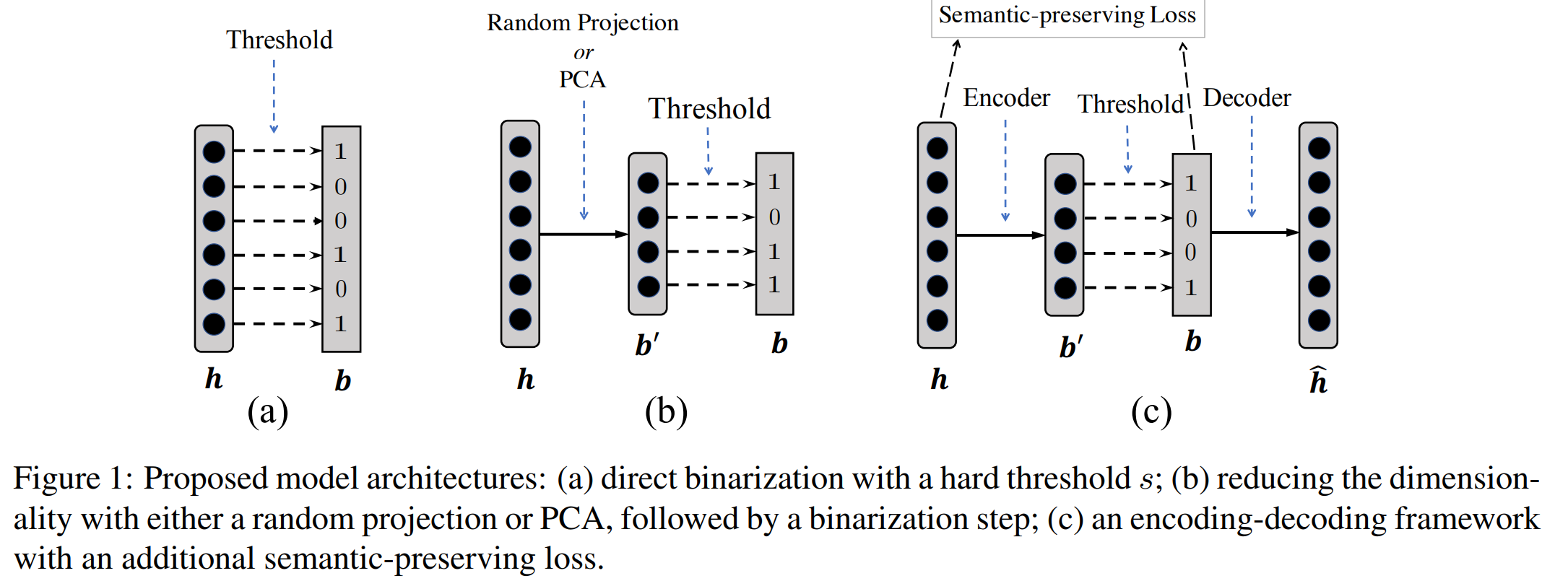
論文では4つの手法が提案されているが、 上記図 (論文より) の(c)について説明する。 (c)はAutoencoderベースのアーキテクチャに基づいて密ベクトルから二値ベクトルへ変換する手法である。 Autoencoderは与えられた入力と同じものを出力するようなモデルである。 ここでは密ベクトルを入力として、 (内部で二値ベクトルへ変換し、) 二値ベクトルに基づいて入力の密ベクトルを出力するように用いる。処理の流れは次の通り。
- 文に対する密ベクトル$\mathbf{h}$を得る
- 出力した密ベクトルを線形変換し、閾値以上の要素を$1$、それ以外を$0$としたベクトル$\mathbf{b}‘$を得る
- 閾値以上の要素を$1$、そうでなければ$0$として変換した二値ベクトル$\mathbf{b}$を得る
- $\mathbf{b}$から密ベクトル$\hat{\mathbf{h}}$を出力する
学習時は$\hat{\mathbf{h}}$が入力$\mathbf{h}$に近づくように二乗誤差に基づいてパラメータを更新する。 ただし二乗誤差は入力の密ベクトルと出力の密ベクトルの要素の差を小さくするような式となっており、 これでは二値ベクトルが二文間の類似度をうまく測れるような情報を保持するように密ベクトルを圧縮できているとは限らない。 そこで密ベクトルのときの類似度の大小関係を、二値ベクトルへ変換した際も保持するような制約を二乗誤差と合わせて学習する。 たとえば文αの密ベクトルに対して、文βの密ベクトルよりも文γの密ベクトルほうがコサイン類似度が高い場合は、二値ベクトルへ変換したあとでも、同様の関係となるほど良い、ということである。 この制約をsemantic-preserving regularizerと呼んでいる。 この学習により、二値ベクトルは元の密ベクトルの情報を保持しつつ、もとの密ベクトルのときの類似度関係を失わないようになりやすくなる。 学習は (おそらくGPU上で) 1時間ほどで収束したとのこと。
実際に文を二値ベクトルへ変換する際はステップ3までの処理を実施し、二つの文の二値ベクトルの間のハミング距離を計算する。




