
Kaggle初参加記録
この一週間休暇を取っていて、多少の暇な時間があったので前から気になっていたKaggleに手を付けてみた。 今回はチュートリアル的に公開されているtitanic号の生存予測タスクに参加した。 他の参加者がブログで公開されている素性を参考に素性を設計した。 予測モデルには以前C++で実装した平均化パーセプトロンを用いた。 Scoreが0.79426 (2017/7/29 16:00時点で1428位/7247位) となった。 Kaggleを続けると、機械学習に関するエンジニア能力が高まりそうで良い。
目次
モデル
生存予測モデルおよび年齢予測モデルには以前C++で実装した平均化パーセプトロンを用いた。 平均化パーセプトロンを採用した積極的な理由があるわけではないのだが、今回はOSSに頼らずに、自分で実装した学習器を使いたかったので、消去法的に採用された。 実践的には広く知られたOSSのほうが、優秀なアルゴリズムが実装されていると思うし、バグの可能性も少ないと思うので、今回のようなアプローチはあまり得策ではないと思う。 おそらくランダムフォレストやSVMなどのモデルを利用する参加者が多い中で、パーセプトロンを利用した数少ない人間になるだろう。
後述するが、本タスクで扱うデータには欠損値が存在する。 そこで、欠損値を予測するためのモデルを別途作成し、値を補完するためのモデルを作成した (これもやはり、平均化パーセプトロン) 。 生存予測モデルへの入力 (素性) を予測するモデルを作成しているので、全体構成としてはいわゆるstackingになっている。
素性
メタデータ分析的に他の方がブログで公開されている素性を参考に設計している。
- 1-of-k表現
- 性別
- 年齢 (0~9, 10~19, 20~29, 30~39, 40~49, 50~というカテゴリに修正している)
- チケット番号
- キャビン
- 乗車地
- チケットのクラス
- 親の人数
- 兄弟の人数
- 肩書 (名前から抽出した次の情報: Mr., Ms., Miss., Master.)
- 運賃 (値の正規化はしていない)
- 組み合わせ素性
- 1.1および{1.2, 1.3, 1.4, 1.5, 1.6, 1.7, 1.8}
- 1.6および{1.4, 1.5, 1.7, 1.8}
(1.2) このタスクで扱うデータでは、欠損値が存在する。例えば年齢は、生存者の予測に有効に働きそう (幼い子どもは優先的に救助されうる) なのだが、欠損値が少なからず存在する。 そこで、年齢が不明な事例に関しては、年齢を予測するためのモデルを事前に作成しておき、そのモデルによって年齢を予測し、補完した。 年齢予測モデルで利用した素性は1.1, 1.3, 1.4, 1.5, 1.6, 1.7, 1.8, 1.9で、予測ラベルは1.2の5クラスとした。精度はあまり高くなく、学習データ中で年齢が存在する事例を用いた交差検定で36%程度となった。
(3) 例えば女性でかつランクの高いチケットで乗船していた人は、そうでない人よりも救助されうるのではないかと考えられるため、素性の組み合わせを陽に与えている。予測モデルは線形分類器なので、素性の組み合わせを明示的に考慮する。
結果の投稿まで
交差検定により、学習データに対してAccuracyが高くなっていたら、結果を投稿して順位を確かめる、というサイクルを何回か繰り返した。 2017/7/29 16:00時点で1428位/7247位となった。Scoreが0.8を超えるとそこそこ良いらしいので、もう少し色々といじるかもしれない。

実験に用いたプログラムはGitHubに公開した。
モデル
交差検定で学習したあるモデルの中身 (重みが大きい上位20件の素性リスト) は次のようになっている。
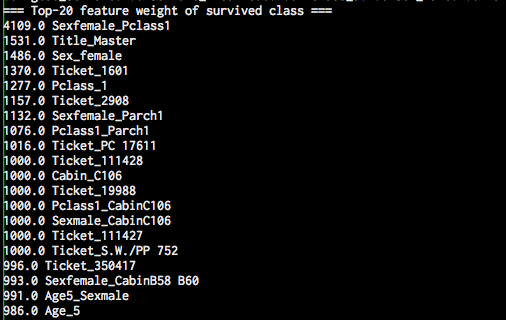
性別が女性でかつチケットのクラスが1 (高級?) とか、肩書がMaster (12歳くらいまでの若い少年 Master (form of address)) であったりすると、生存の可能性が他の人よりも高いという感じの学習結果になっている。
反省点
ある修正によって、Accuracyがどれくらい変わるかみたいなログを取っていなかったので、方策がよかったのか、悪かったのかが頭のなかに曖昧にしか残らなくなってしまった。本当は修正によってAccuracyがどうなった、という情報をGitなどで管理するほうがよい。
感想
とにかく有効そうな素性あるいはモデルをどんどん試す、というサイクルをひたすら回す感じで、実用的なエンジニアリング能力 (素性、モデルの設計能力や問題設定能力、あるいは効率的な実験の方法) が身につきそうだった。また、他の参加者と全く同じ問題を溶いているので、他の人が考えたことを共有してくれると、知見がたまって良いと思った。




