
Active Sampling for Entity Matching (KDD 2012)を読んだ
proceeding (pdf), slide (html), journal (pdf)
KDD 2012の時点では元々Yahoo! Researchにいた著者らがjournalでは所属がみんなばらばらになっているので興味があって調べてみたけど、 マリッサ・メイヤーのYahoo! CEO就任は2012年7月17日、KDD 2012は2012年8月中旬、 おそらくその後にjournalを出しているのでマリッサ・メイヤーの就任は転職に影響したのだろうかという 余計な詮索をしていた。 journalのpublish dateはMarch 2010となっているけどreferenceにはそれ以降の論文もあるし、 これは2010に出たjournalではないらしくて時系列がどうなっているのか混乱した。
概要
entity matchingでは正例に対して負例がとても多く、学習にはprecisionがしきい値以上であるような 制約を満たすようにrecallを最大化するactive learningアルゴリズムが提案されている。 ただ先行研究のアルゴリズムはlabel complexity、computational complexityともに高いので 提案手法では近似的にprecision制約付きのrecall問題を解く方法を提案してそれが先行研究 に比べて早く、しかも精度もよく学習できることを示している。
発表資料
以下メモ。
Convex hull algorithm
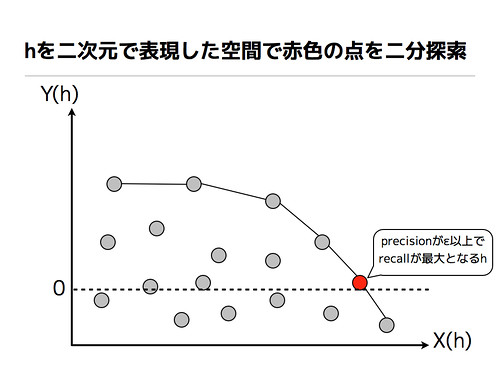
Rejection sampling algorithm
black boxの学習をおこなう前に呼び出されるアルゴリズム。 気持ちを理解するにはMachined Learnings: Cost-Sensitive Binary Classification and Active Learningが詳しい。 要約すると分類器の学習にはfalse positiveやfalse nagativeに対してどちらをより優先して 少なくするような重み付けをした目的関数を最適化する方法があるのだが、この重みはラベル が付いていないサンプルに関しては人間にラベルの問い合わせをおこなわないとできない (正解 が正例、 負例のどちらかがわからないとα、1-αのどちらを掛けたらよいか決められない) 。 今の状況では、active learningのアルゴリズムがラベルの問い合わせをおこなったサンプル についてのみ正解のラベルがわかっている。そこで、ラベルの問い合わせをしたサンプルのみ 正例の場合は確率α、負例の場合は確率1-αで訓練データとして扱い、そうでなければ棄却をする。 棄却されなかったサンプルの集合の期待値を計算するともとの目的関数と同じになる。
この方法はラベルがわかっている場合には馬鹿馬鹿しい方法に見えるけど、ラベルが一部しか 見えない場合には現実的な方法である。
合わせて読みたい
コンピュータが政治をする時代(あるいは,行列とテキストの結合モデル)について - a lonely miner




